





|
Listen to this story
|
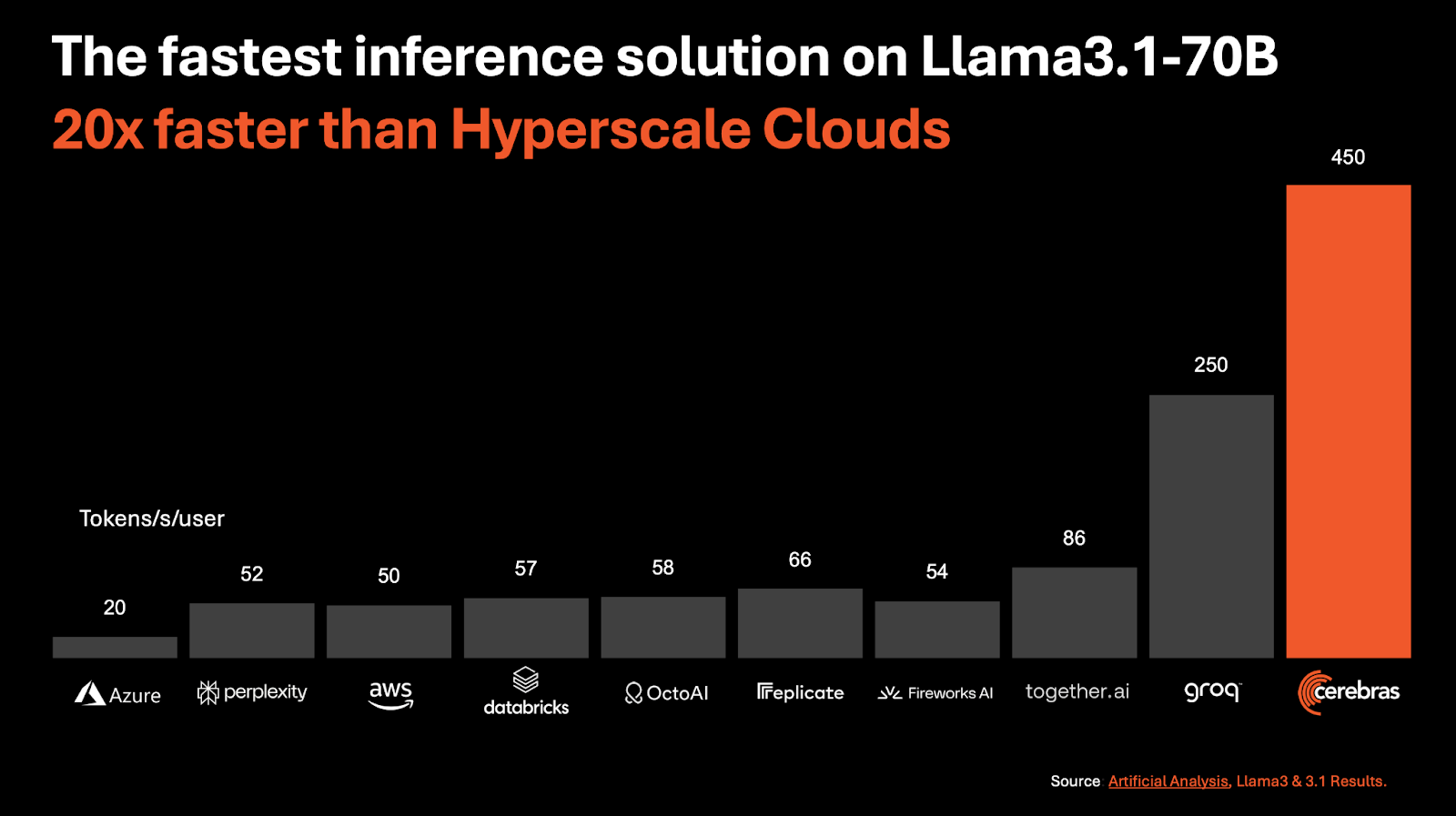
Cerebras Systems today announced its new AI inference solution, Cerebras Inference, which it claims is the fastest in the world. The solution delivers 1,800 tokens per second for the Llama 3.1 8B model and 450 tokens per second for the Llama 3.1 70B model, making it 20 times faster than NVIDIA GPU-based hyperscale clouds.
Cerebras Inference is priced at 10 cents per million tokens for Llama 3.1 8B and 60 cents per million tokens for Llama 3.1 70B, and is available to developers through API access.
The solution is powered by the third-generation Wafer Scale Engine (WSE-3), which enables it to run Llama 3.1 models 20 times faster than GPU solutions at one-fifth the cost. The WSE-3 integrates 44GB of SRAM on a single chip, eliminating the need for external memory and providing 21 petabytes per second of aggregate memory bandwidth, which is 7,000 times greater than that of an NVIDIA H100 GPU.
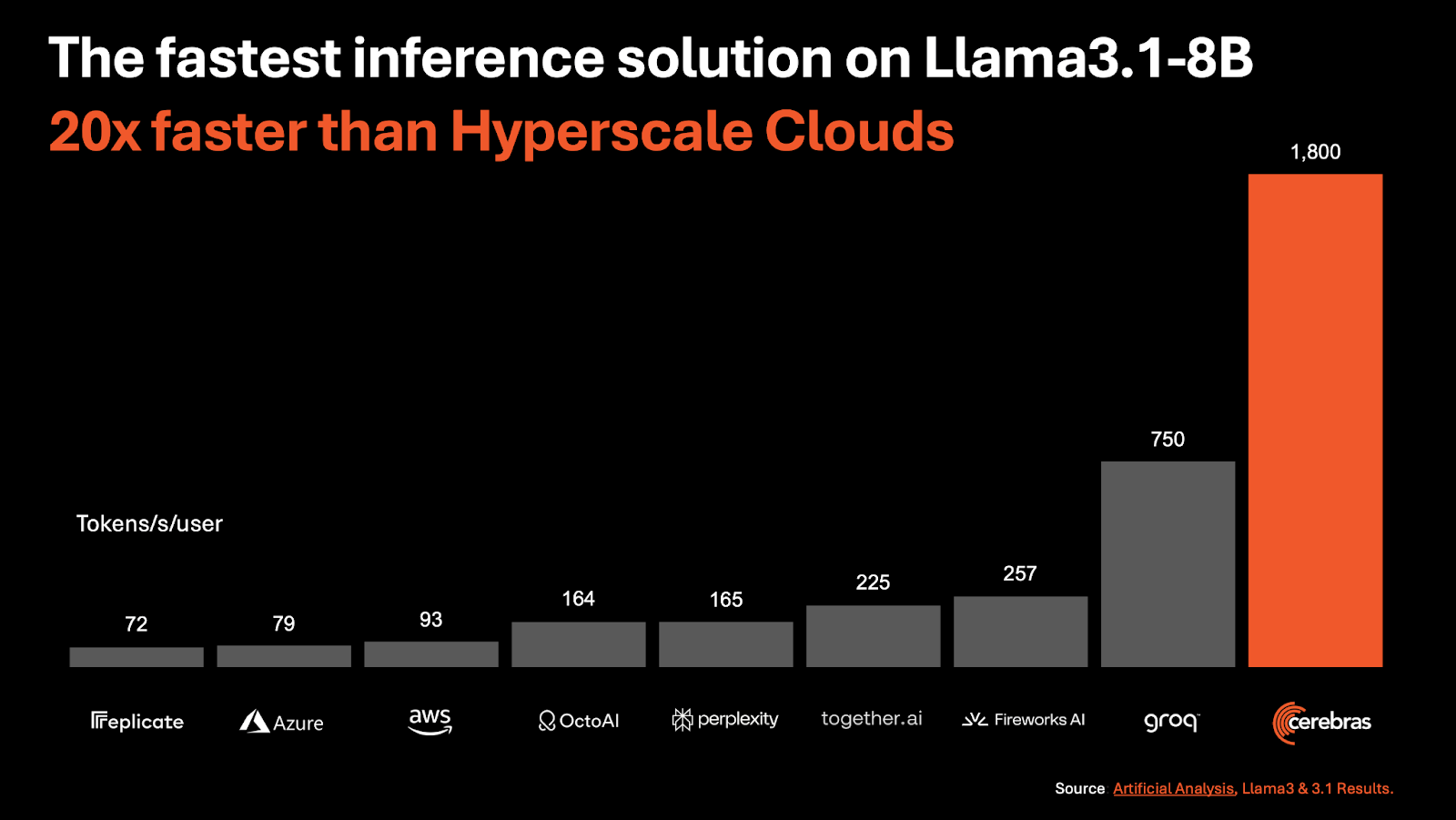
Cerebras addresses the inherent memory bandwidth limitations of GPUs, which require models to be moved from memory to compute cores for every output token. This process results in slow inference speeds, particularly for large language models like Llama 3.1-70B, which has 70 billion parameters and requires 140GB of memory.
Cerebras Inference supports models from billions to trillions of parameters. For models exceeding the memory capacity of a single wafer, Cerebras splits them at layer boundaries and maps them to multiple CS-3 systems. Larger models, such as Llama3-405B and Mistral Large, are expected to be supported in the coming weeks.
Cerebras Inference operates using 16-bit model weights, preserving the accuracy of the original Llama 3.1 models released by Meta. The solution offers developers chat and API access, with an initial offering of 1 million free tokens daily.
The company emphasises that the speed of inference is not just a matter of performance metrics but also enables more complex AI workflows and real-time large language model intelligence. Cerebras notes that techniques like scaffolding, which require significantly more tokens at runtime, are only feasible with its hardware.
Cerebras Inference aims to set a new standard for large language model development and deployment, offering both high-speed training and inference capabilities. The company anticipates that the speed and cost advantages will open up new possibilities for AI applications.

























