





In a bid to support the largest models, American semiconductor company Cerebras recently unveiled the world’s first multi-million core AI cluster architecture. This new technology handles neural networks with up to 120 trillion parameters. It is said to have the computing power of a human brain.
Large language models like Microsoft NLG, OpenAI’s GPT-3, NVIDIA’s Megatron, and BAAI’s Wu Dao 2.0 have grown exponentially in the last few years. To run these models at scale, companies require a cluster of graphics processors, megawatts of power, and dedicated teams to operate them. As a result, chips that support AI at scale have become crucial more than ever before, focusing on scaling massive memory, compute, and communication.

(Source: Cerebras)
The Rise of AI Chips
According to Technavio, the artificial intelligence (AI) chip market is expected to grow at $73.49 billion, growing at a CAGR of 51 per cent during the forecast period (2021-2025). Two years back, McKinsey reported that by 2025, AI-related semiconductors could account for almost 20 per cent of all demand, accounting for $65 billion in revenue. If this growth materialises as expected, semiconductor companies will be positioned to capture 40 to 50 per cent of the total market share.
Some notable companies that make chips used to train AI models include Alphabet, Broadcom, Intel, NVIDIA, Qualcomm, Samsung Electronics, TSMC, and Graphcore. Recently, Tesla also unveiled its supercomputer called ‘Dojo,’ which has a capacity of over an exaflop, which is one quintillion (1018) floating-point operations per second. This chip is mainly used for computer vision for self-driving cars using cameras.
Tesla has been collecting from over 1 million vehicles to train the neural network using its in-house chip. Before this, Tesla used the NVIDIA Drive PX2 chip to implement their autopilot and scale the production of autonomous vehicles. The chip’s configuration consists of a mobile processor that can operate at 10 watts and is converted to a multi-chip configuration with two mobile processors and two discrete GPUs, delivering 24 trillion deep learning operations per second.
Another chip from NVIDIA PX Xavier consumes only 20 watts of power while delivering 20 TOPS of performance. It is packed with 7 billion transistors. NVIDIA Drive Pegasus uses power for two Xavier SoCs (system on chips) and NVIDIA’s Turing architecture to ensure the capacity of 320 TOPS while consuming 500 watts. The company is designing this platform for Level 4 and Level 5 autonomy. On the other hand, NVIDIA’s GA100 Ampere SoC is at the top with 54 billion transistors.
In April this year, NVIDIA also unveiled a new processor called Grace, named after computer scientist Grace Hopper. This chip is designed to accelerate high performing computing and artificial intelligence (AI) workloads at data centres. It is said to deliver up to 30x higher aggregate bandwidth than today’s fastest servers and up to 10x higher performance for applications running terabytes of data.
In the same month, Intel had also launched its most advanced and highest performing processor data centre — 3rd generation Intel Xeon scalable processor, aka Ice Lake. Another chip, Intel Mobileye Q4, can perform 2.5 tops while consuming 3 watts of power. This chip has generic multi-thread CPU cores, making it a robust computing platform for ADAS/AV applications. It supports a 40 Gbps data bandwidth.
Google has also been working on developing AI chips for years. In June 2021, in a paper, ‘A graph placement methodology for fast chip design,’ the researchers revealed an upcoming version of Google’s own tensor processing unit (TPU) chips, which are optimised for AI computation. Recently, Google announced that it had developed a custom-built SoC, Tensor, to power Pixel phones.
Cerebras AI chip
Built on the second generation Cerebras wafer-scale engine (WSE-2), the company looks to address the fundamental challenges using a holistic systems approach for extreme scale. It has designed a purpose-built solution for each type of memory and compute that the neural network needs to untangle and simplify the scaling problem.
Cerebras calls this new execution mode ‘weight streaming.’ It unlocks unique flexibility, allowing independent scaling of the model size and the training speed. For example, a single CS-2 system can support models up to 120 trillion parameters. “To speed up training, we can cluster up to 192 systems with near-linear performance scaling,” said the Cerebras team.
Here’s how it Works
In this mode, they store the model weights in a new memory extension technology called MemoryX and stream the weights onto the CS-2 systems to compute each layer of the network, one layer at a time, as shown in the image below.
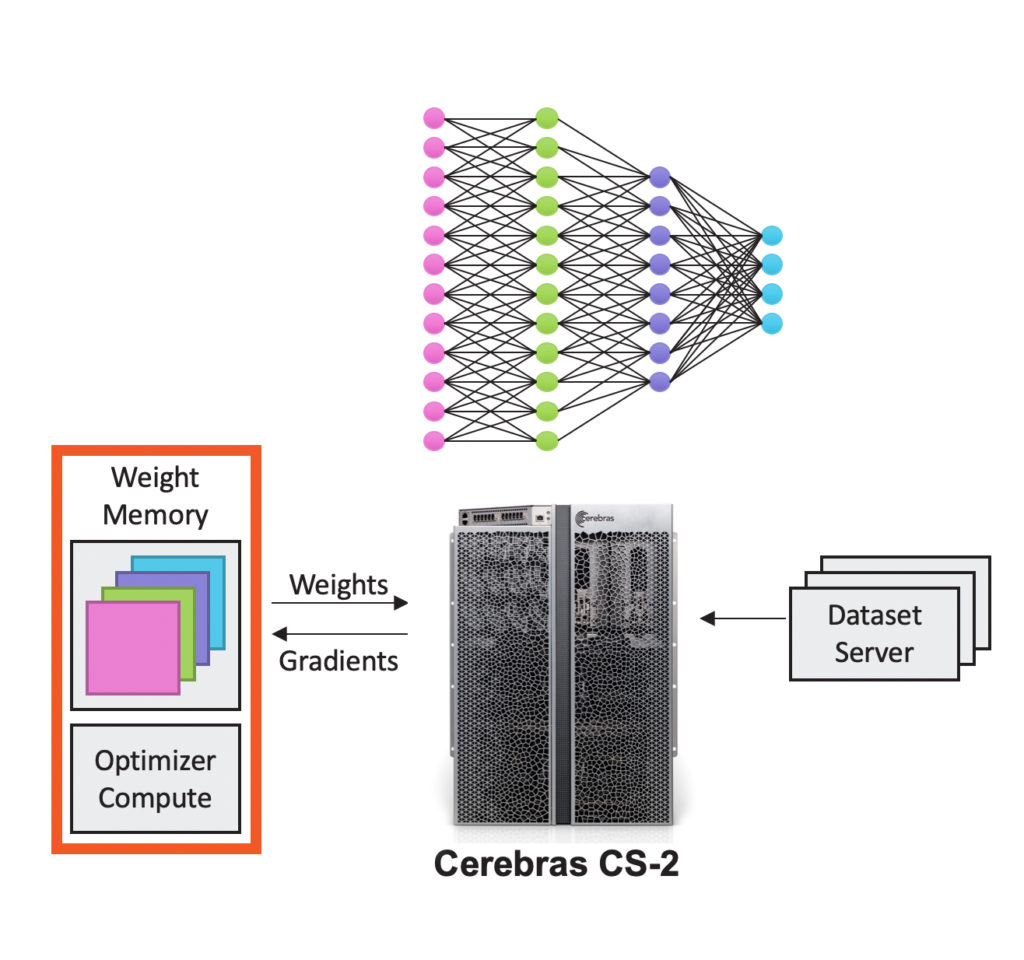
(Source: Cerebras)
On the backward pass, the gradients are streamed in the opposite direction back to the MemoryX, where the weight update is performed in time to be used for the next iteration of training. Here, it has also introduced an interconnect fabric technology called SwarmX, which allows it to scale the number of CS-2 systems near-linearly for extreme, large-scale models.
What’s more?
Besides scaling capacity and performance, Cerebras’ architecture enables vast acceleration for sparse neural networks. It uses fine-grained dataflow scheduling to trigger computations only for useful work. Thus, allowing them to save power and achieve 10X weight sparsity speedup.
Further, researchers can use this architecture to compile the neural network mapping for a single CS-2 system, and the Cerebras software takes care of execution as the model scale, thus, eliminating the traditional distributed AI intricacies of memory partitioning, coordination, and synchronisation across thousands of small devices.


























