





|
Listen to this story
|
In a collaborated effort with Waymo & University of Southern California, Meta FAIR released its research on the importance of multi-modal generative models. Transfusion aims to unite and simplify the gap between discrete sequence modeling and continuous media generation.
The Transfusion Model
The model is trained equally on text and image. Per Meta, Transfusion is more advanced than quantising images and training a language model over discrete image tokens. The model’s performance can be enhanced through “modality-specific” encoding and decoding layers. The model predicts the next word in a sequence. Trained on improving predictions, it reduces the difference between guessing and actual words. It is imperative to note that with 7 billion parameters and 2 trillion multi modal tokens, Transfusion is at par with other larger models that create image and text – and outperforms models like DALL-E 2 and SDXL. It works better than Chameleon as it takes lesser computing power and generates better results.
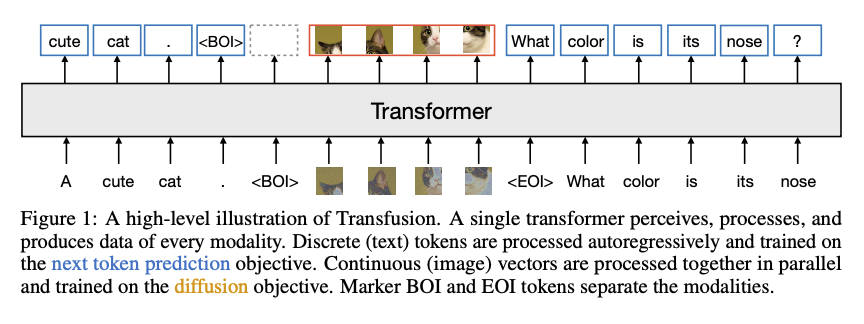
One limitation is perhaps that diffusion models do not perform at par with traditional language models. A lot of research is yet to be done in this area to improve overall performance.
Transformer’s Uniqueness & the Future of Innovation in AI Research
What differentiates Transformer from the rest is its unified architecture that runs end to end to generate text and images. Existing models like Flamingo, LLaVA, GILL, and DreamLLM combine separate architectures for different types of data, which are trained separately.
The goal of this Transfusion is to synergise two modalities in a single joint model – with each of them fulfilling their objective. The incentives are that these are versatile, resource efficient, and cost effective for handling different types of data without any additional costs.


























