





After Llama 3.1 was leaked, Meta has officially released Llama 3.1 405B, a new frontier-level open source AI model, alongside its 70B and 8B versions. Meta is offering developers free access to its weights and code, and enabling fine-tuning, distillation, and deployment.
The Llama 3.1 405B model performs on par with the best closed models. It supports a context length of 128k, eight languages, and offers robust capabilities in code generation, complex reasoning, and tool use.
“Meta AI is on track to reach our goal of becoming the most used AI assistant in the world by the end of the year,” said Meta chief Mark Zuckerberg. He also dropped hints about the upcoming features in Meta AI.
“Over the next couple of weeks, we’re also adding a couple of new features. Meta AI Imagine, which generates images as fast as you type, will also let you put yourself in your images in any style and do almost anything that you can think of. So I think that’s going to be quite a bit of fun. We’re also getting closer to releasing a tool that you can use to create your own AIs to interact with across our apps. More on that soon,” added Zuckerberg.
Meta has introduced the Llama Stack API for easy integration, supported by an ecosystem of over 25 partners, including AWS, NVIDIA, Databricks, Groq, Dell, Azure, and Google Cloud.
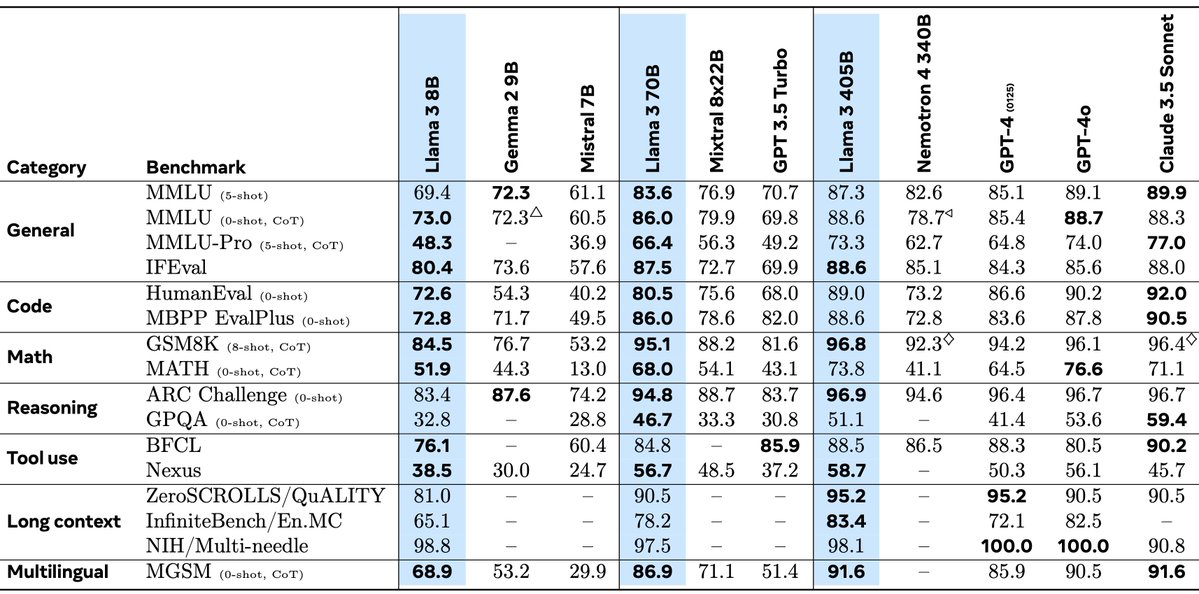
For this release, Meta evaluated performance on over 150 benchmark datasets across various languages. Extensive human evaluations were also conducted, comparing Llama 3.1 with competing models in real-world scenarios.
The evaluation suggests that Llama 3.1 is competitive with leading foundation models such as GPT-4, GPT-4o, and Claude 3.5 Sonnet. Additionally, the smaller models in the Llama 3.1 series are competitive with closed and open models with similar parameter counts.
Zuckerberg said that this is the Linux-like moment in the world of AI. “I think that open source AI is going to become the industry standard just like Linux did. It gives you control to customize and run your own models. You don’t have to send your data to another company, and it’s more affordable,” he said.
Llama 3.1 is designed to enable new workflows like synthetic data generation and model distillation. It is available for testing in the US on WhatsApp and at meta.ai, where users can pose challenging math or coding questions.
The model was trained on over 15 trillion tokens using over 16,000 H100 GPUs, making it Meta’s largest and most ambitious model to date. The training process involved significant optimisations, including a standard decoder-only transformer model architecture and iterative post-training procedures. These efforts aimed to maximize training stability and improve the quality of synthetic data.
To support large-scale production inference, Meta quantised the models from 16-bit to 8-bit numerics, reducing compute requirements and enabling the model to run within a single server node. This advancement is expected to drive innovation and exploration in AI applications, offering unprecedented growth opportunities.

























