


|
Listen to this story
|
Retrieval-augmented generation (RAG) models combine the power of large language models (LLMs) with external knowledge retrieval to produce more accurate and contextually relevant responses.
NVIDIA, in collaboration with AIM, recently hosted an in-depth online workshop led by Sagar Desai, a senior solutions architect specialising in LLMs and production deployment using NVIDIA’s stack. This workshop, part of the NVIDIA AI Forum Community, aimed at exploring advanced techniques and best practices for optimising RAG models to achieve enterprise-grade accuracy.
You can now view the workshop recording here
The Growing Relevance of Generative AI in Enterprises
The workshop started with Sagar explaining the key points about generative AI, the technology that allows machines to generate content, and how it has been making significant inroads across various industries.
From language processing to computer vision and beyond, generative AI is becoming a default skill for developers and is expected to become even more pervasive in the coming years.
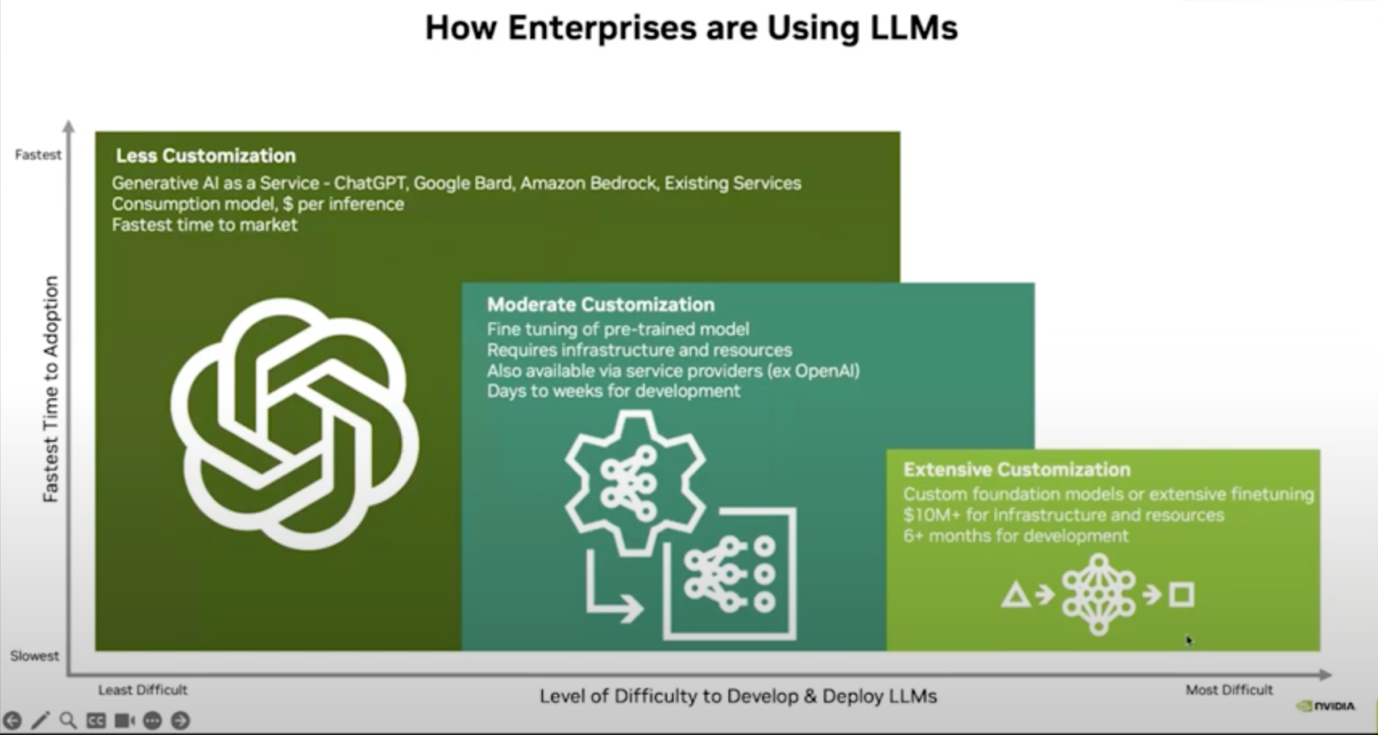
While LLMs like GPT-4 are powerful, they face challenges in handling domain-specific or real-time information. RAG offers a solution by integrating external data sources into AI outputs, making responses more accurate and contextually relevant.
This capability is crucial for enterprises that need to incorporate proprietary or up-to-date information into their AI-driven processes, ensuring the content generated is both precise and relevant to their specific needs.
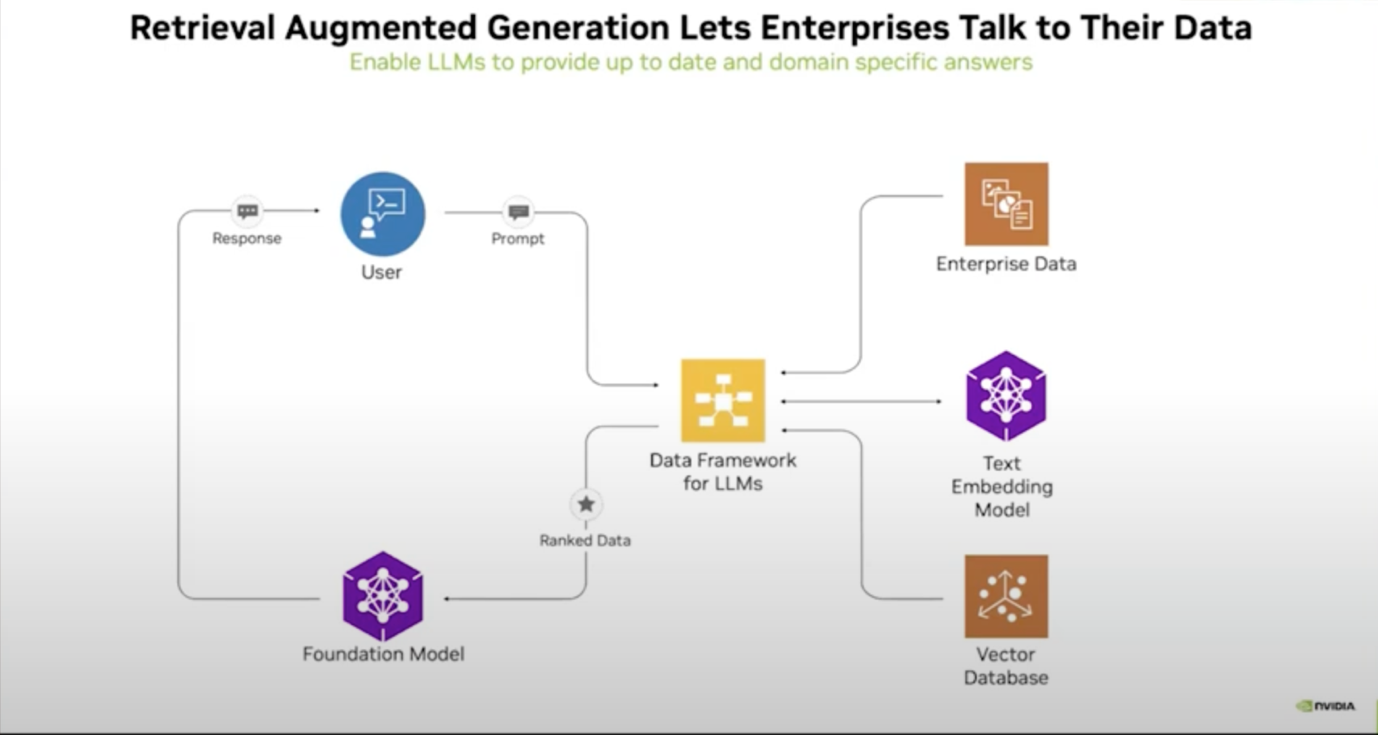
Key Techniques for Optimising RAG Models
During the workshop, Desai delved into several advanced techniques for optimising RAG models to achieve enterprise-grade accuracy. These techniques include:
- Query Writing: Crafting effective queries is essential for guiding the retrieval system in fetching the most relevant information. Desai emphasised the importance of understanding the context and intent behind a query to ensure that the retrieved data aligns with the user’s needs.
- Embedding Fine-Tuning: Embeddings, which are vector representations of text, play a crucial role in how LLMs and retrieval systems understand and process information. Fine-tuning these embeddings on domain-specific data can significantly improve the relevance and accuracy of the retrieved information.
- Re-ranking Strategies: After retrieving a set of potential responses, re-ranking techniques can be applied to prioritise the most relevant and accurate answers. Desai discussed various re-ranking methods that can be used to enhance the quality of the final output.
- Chunking Strategy: The workshop highlighted the importance of an effective chunking strategy when dealing with large documents or datasets. Splitting data into appropriately sized chunks ensures that the model can process and retrieve information more efficiently.
- Hybrid Embedding Models: Desai introduced the concept of hybrid embedding models, which combine semantic embeddings with keyword-based retrieval techniques (such as BM25) to improve the accuracy of the retrieval process. This approach allows for a more nuanced understanding of the query and better alignment with the user’s intent.
You can now view the workshop recording here
Scaling RAG Models for Enterprise Applications
One of the critical challenges in deploying RAG models at the enterprise level is ensuring that they can scale effectively while maintaining high accuracy and reliability. Desai discussed several strategies for scaling RAG models, including:
- Utilising Advanced Hardware: NVIDIA’s stack, including the DGX systems and cloud solutions, provides the computational power needed to handle the massive demands of training and deploying RAG models. These systems are optimised for parallel computation, making them ideal for scaling LLMs and RAG models.
- Leveraging Kubernetes for Inference Scaling: Kubernetes, a popular container orchestration platform, was highlighted as a powerful tool for managing and scaling AI inference workloads. By deploying RAG models within a Kubernetes environment, enterprises can achieve greater flexibility and efficiency in handling large-scale AI deployments.
- Implementing Effective Indexing Mechanisms: Efficient indexing is crucial for the performance of RAG models, particularly when dealing with large datasets. Desai emphasised the importance of using vector databases, such as FAISS and Milvus, to streamline the retrieval process and improve the speed and accuracy of the system.
Best Practices for Deploying RAG Models in Production
Deploying RAG models in production environments requires careful planning and adherence to best practices to ensure that the models perform reliably and securely.
Key takeaways from the workshop included:
- Ensuring Data Security and Privacy: Enterprises must implement robust security measures to protect sensitive data used in training and deploying RAG models. This includes using secure APIs, encryption, and access controls to safeguard proprietary information.
- Continuous Monitoring and Evaluation: Sagar underscored the importance of ongoing monitoring and evaluation of RAG models in production. This involves regularly assessing the model’s performance, accuracy, and relevance to ensure that it continues to meet enterprise requirements.
- Fine-Tuning and Domain Adaptation: To maintain the accuracy and relevance of RAG models, enterprises should continuously fine-tune and adapt the models to their specific domains. This includes retraining the models on new data and adjusting the retrieval system to reflect changes in the knowledge base.
The Future of RAG Models in Enterprise AI
The NVIDIA workshop provided valuable insights into the advanced techniques and best practices for optimising RAG models to achieve enterprise-grade accuracy. As enterprises continue to adopt AI at scale, RAG models offer a powerful solution for overcoming the limitations of traditional LLMs by integrating real-time, domain-specific, and proprietary information into AI-generated content.
By leveraging the techniques and strategies discussed in the workshop, enterprises can unlock the full potential of RAG models, enabling them to deliver more accurate, reliable, and contextually relevant AI solutions.
For AI professionals and enterprises looking to stay ahead of the curve, attending workshops and training sessions like NVIDIA’s is essential. These events provide a platform for learning, networking, and exploring the latest advancements in AI technology, ensuring that participants are well-equipped to tackle the challenges and opportunities in this rapidly evolving field.
You can now view the workshop recording here
| Master the latest AI advancements with comprehensive, full-day workshops and earn technical certifications from NVIDIA experts. To learn more, attend the NVIDIA AI Summit India, scheduled for October 23–25, 2024, at Jio World Convention Centre — Mumbai. Register here. |






















