





Representation learning is a very important aspect of machine learning which automatically discovers the feature patterns in the data. When the machine is provided with the data, it learns the representation itself without any human intervention. The goal of representation learning is to train machine learning algorithms to learn useful representations, such as those that are interpretable, incorporate latent features, or can be used for transfer learning. In this article, we will discuss the concept of representation learning along with its need and different approaches. The major points to be covered in this article are listed below.
Let’s start the discussion by understanding what is the actual need for representation learning.
Need of Representation Learning
Assume you’re developing a machine-learning algorithm to predict dog breeds based on pictures. Because image data provides all of the answers, the engineer must rely heavily on it when developing the algorithm. Each observation or feature in the data describes the qualities of the dogs. The machine learning system that predicts the outcome must comprehend how each attribute interacts with other outcomes such as Pug, Golden Retriever, and so on.
As a result, if there is any noise or irregularity in the input, the result can be drastically different, which is a risk with most machine learning algorithms. The majority of machine learning algorithms have only a basic understanding of the data. So in such cases, the solution is to provide a more abstract representation of data. It’s impossible to tell which features should be extracted for many tasks. This is where the concept of representation learning takes shape.
What is Representation Learning?
Representation learning is a class of machine learning approaches that allow a system to discover the representations required for feature detection or classification from raw data. The requirement for manual feature engineering is reduced by allowing a machine to learn the features and apply them to a given activity.
In representation learning, data is sent into the machine, and it learns the representation on its own. It is a way of determining a data representation of the features, the distance function, and the similarity function that determines how the predictive model will perform. Representation learning works by reducing high-dimensional data to low-dimensional data, making it easier to discover patterns and anomalies while also providing a better understanding of the data’s overall behaviour.
Basically, Machine learning tasks such as classification frequently demand input that is mathematically and computationally convenient to process, which motivates representation learning. Real-world data, such as photos, video, and sensor data, has resisted attempts to define certain qualities algorithmically. An approach is to examine the data for such traits or representations rather than depending on explicit techniques.
Methods of Representation Learning
We must employ representation learning to ensure that the model provides invariant and untangled outcomes in order to increase its accuracy and performance. In this section, we’ll look at how representation learning can improve the model’s performance in three different learning frameworks: supervised learning, unsupervised learning.
1. Supervised Learning
This is referred to as supervised learning when the ML or DL model maps the input X to the output Y. The computer tries to correct itself by comparing model output to ground truth, and the learning process optimizes the mapping from input to output. This process is repeated until the optimization function reaches global minima.
Even when the optimization function reaches the global minima, new data does not always perform well, resulting in overfitting. While supervised learning does not necessitate a significant amount of data to learn the mapping from input to output, it does necessitate the learned features. The prediction accuracy can improve by up to 17 percent when the learned attributes are incorporated into the supervised learning algorithm.
Using labelled input data, features are learned in supervised feature learning. Supervised neural networks, multilayer perceptrons, and (supervised) dictionary learning are some examples.
2. Unsupervised Learning
Unsupervised learning is a sort of machine learning in which the labels are ignored in favour of the observation itself. Unsupervised learning isn’t used for classification or regression; instead, it’s used to uncover underlying patterns, cluster data, denoise it, detect outliers, and decompose data, among other things.
When working with data x, we must be very careful about whatever features z we use to ensure that the patterns produced are accurate. It has been observed that having more data does not always imply having better representations. We must be careful to develop a model that is both flexible and expressive so that the extracted features can convey critical information.
Unsupervised feature learning learns features from unlabeled input data by following the methods such as Dictionary learning, independent component analysis, autoencoders, matrix factorization, and various forms of clustering are among examples.
In the next section, we will see more about these methods and workflow, how they learn the representation in detail.
Supervised Learning Algorithms
1. Supervised Dictionary Learning
Dictionary learning creates a set of representative elements (dictionary) from the input data, allowing each data point to be represented as a weighted sum of the representative elements. By minimizing the average representation error (across the input data) and applying L1 regularization to the weights, the dictionary items and weights may be obtained i.e., the representation of each data point has only a few nonzero weights.
For optimizing dictionary elements, supervised dictionary learning takes advantage of both the structure underlying the input data and the labels. The supervised dictionary learning technique uses dictionary learning to solve classification issues by optimizing dictionary elements, data point weights, and classifier parameters based on the input data.
A minimization problem is formulated, with the objective function consisting of the classification error, the representation error, an L1 regularization on the representing weights for each data point (to enable sparse data representation), and an L2 regularization on the parameters of the classification algorithm.
2. Multi-Layer Perceptron
The perceptron is the most basic neural unit, consisting of a succession of inputs and weights that are compared to the ground truth. A multi-layer perceptron, or MLP, is a feed-forward neural network made up of layers of perceptron units. MLP is made up of three-node layers: an input, a hidden layer, and an output layer. MLP is commonly referred to as the vanilla neural network because it is a very basic artificial neural network.
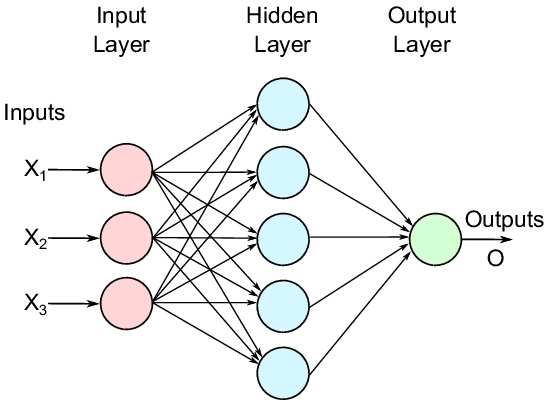
This notion serves as a foundation for hidden variables and representation learning. Our goal in this theorem is to determine the variables or required weights that can represent the underlying distribution of the entire data so that when we plug those variables or required weights into unknown data, we receive results that are almost identical to the original data. In a word, artificial neural networks (ANN) assist us in extracting meaningful patterns from a dataset.
3. Neural Networks
Neural networks are a class of learning algorithms that employ a “network” of interconnected nodes in various layers. It’s based on the animal nervous system, with nodes resembling neurons and edges resembling synapses. The network establishes computational rules for passing input data from the network’s input layer to the network’s output layer, and each edge has an associated weight.
The relationship between the input and output layers, which is parameterized by the weights, is described by a network function associated with a neural network. Various learning tasks can be achieved by minimizing a cost function over the network function (w) with correctly defined network functions.
Unsupervised Learning Algorithms
Learning Representation from unlabeled data is referred to as unsupervised feature learning. Unsupervised Representation learning frequently seeks to uncover low-dimensional features that encapsulate some structure beneath the high-dimensional input data.
1. K-Means Clustering
K-means clustering is a vector quantization approach. An n-vector set is divided into k clusters (i.e. subsets) via K-means clustering, with each vector belonging to the cluster with the closest mean. Despite the use of inferior greedy techniques, the problem is computationally NP-hard.
K-means clustering divides an unlabeled collection of inputs into k groups before obtaining centroids-based features. These characteristics can be honed in a variety of ways. The simplest method is to add k binary features to each sample, with each feature j having a value of one of the k-means learned jth centroid is closest to the sample under consideration. Cluster distances can be used as features after being processed with a radial basis function.
2. Local Linear Embedding
LLE is a nonlinear learning strategy for constructing low-dimensional neighbour-preserving representations from high-dimensional (unlabeled) input. LLE’s main goal is to reconstruct high-dimensional data using lower-dimensional points while keeping some geometric elements of the original data set’s neighbours.
There are two major steps in LLE. The first step is “neighbour-preserving,” in which each input data point Xi is reconstructed as a weighted sum of K nearest neighbour data points, with the optimal weights determined by minimizing the average squared reconstruction error (i.e., the difference between an input point and its reconstruction) while keeping the weights associated with each point equal to one.
The second stage involves “dimension reduction,” which entails searching for vectors in a lower-dimensional space that reduce the representation error while still using the optimal weights from the previous step.
The weights are optimized given fixed data in the first stage, which can be solved as a least-squares problem. Lower-dimensional points are optimized with fixed weights in the second phase, which can be solved using sparse eigenvalue decomposition.
3. Unsupervised Dictionary Mining
For optimizing dictionary elements, unsupervised dictionary learning does not use data labels and instead relies on the structure underlying the data. Sparse coding, which seeks to learn basic functions (dictionary elements) for data representation from unlabeled input data, is an example of unsupervised dictionary learning.
When the number of vocabulary items exceeds the dimension of the input data, sparse coding can be used to learn overcomplete dictionaries. K-SVD is an algorithm for learning a dictionary of elements that allows for sparse representation.
4. Deep Architectures Methods
Deep learning architectures for feature learning are inspired by the hierarchical architecture of the biological brain system, which stacks numerous layers of learning nodes. The premise of distributed representation is typically used to construct these architectures: observable data is generated by the interactions of many diverse components at several levels.
5. Restricted Boltzmann Machine (RBMs)
In multilayer learning frameworks, RBMs (restricted Boltzmann machines) are widely used as building blocks. An RBM is a bipartite undirected network having a set of binary hidden variables, visible variables, and edges connecting the hidden and visible nodes. It’s a variant of the more general Boltzmann machines, with the added constraint of no intra-node connections. In an RBM, each edge has a weight assigned to it. The connections and weights define an energy function that can be used to generate a combined distribution of visible and hidden nodes.
For unsupervised representation learning, an RBM can be thought of as a single-layer design. The visible variables, in particular, relate to the input data, whereas the hidden variables correspond to the feature detectors. Hinton’s contrastive divergence (CD) approach can be used to train the weights by maximizing the probability of visible variables.
6. Autoencoders
Deep network representations have been found to be insensitive to complex noise or data conflicts. This can be linked to the architecture to some extent. The employment of convolutional layers and max-pooling, for example, can be proven to produce transformation insensitivity.

Autoencoders are therefore neural networks that may be taught to do representation learning. Autoencoders seek to duplicate their input to their output using an encoder and a decoder. Autoencoders are typically trained via recirculation, a learning process that compares the activation of the input network to the activation of the reconstructed input.
Final Words
Unlike typical learning tasks like classification, which has the end goal of reducing misclassifications, representation learning is an intermediate goal of machine learning making it difficult to articulate a straight and obvious training target. In this post, we understood how to overcome such difficulties from scratch. From the starting, we have seen what was the actual need for this method and understood different methodologies in supervised, unsupervised, and some deep learning frameworks.


































