|
Listen to this story
|
Even though India’s contribution to Indic LLMs has skyrocketed in the last year, the lack of open-source pipelines for low and mid-resource languages hinders their representation in LLM training datasets.
To address this, AI4Bharat has created IndicLLMSuite, a collection of resources for Indic LLMs covering 22 languages with 251 billion tokens and 74.8 million instruction-response pairs. Let’s take a look at some of the kit’s key resources.
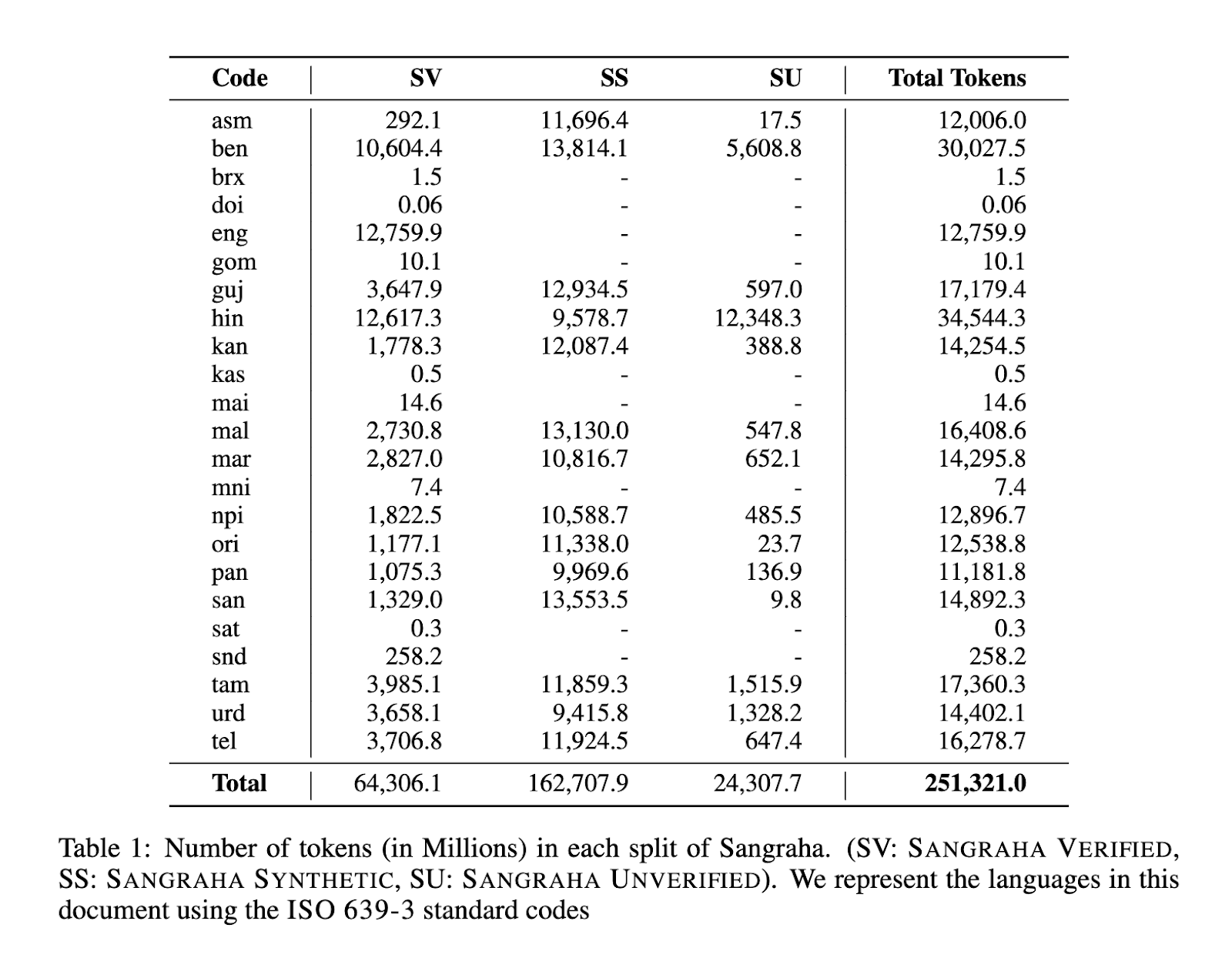
Sangraha
This includes data for pre-training data containing 251B tokens summed up over 22 languages, extracted from curated URLs, existing multilingual corpora, and large-scale translations.
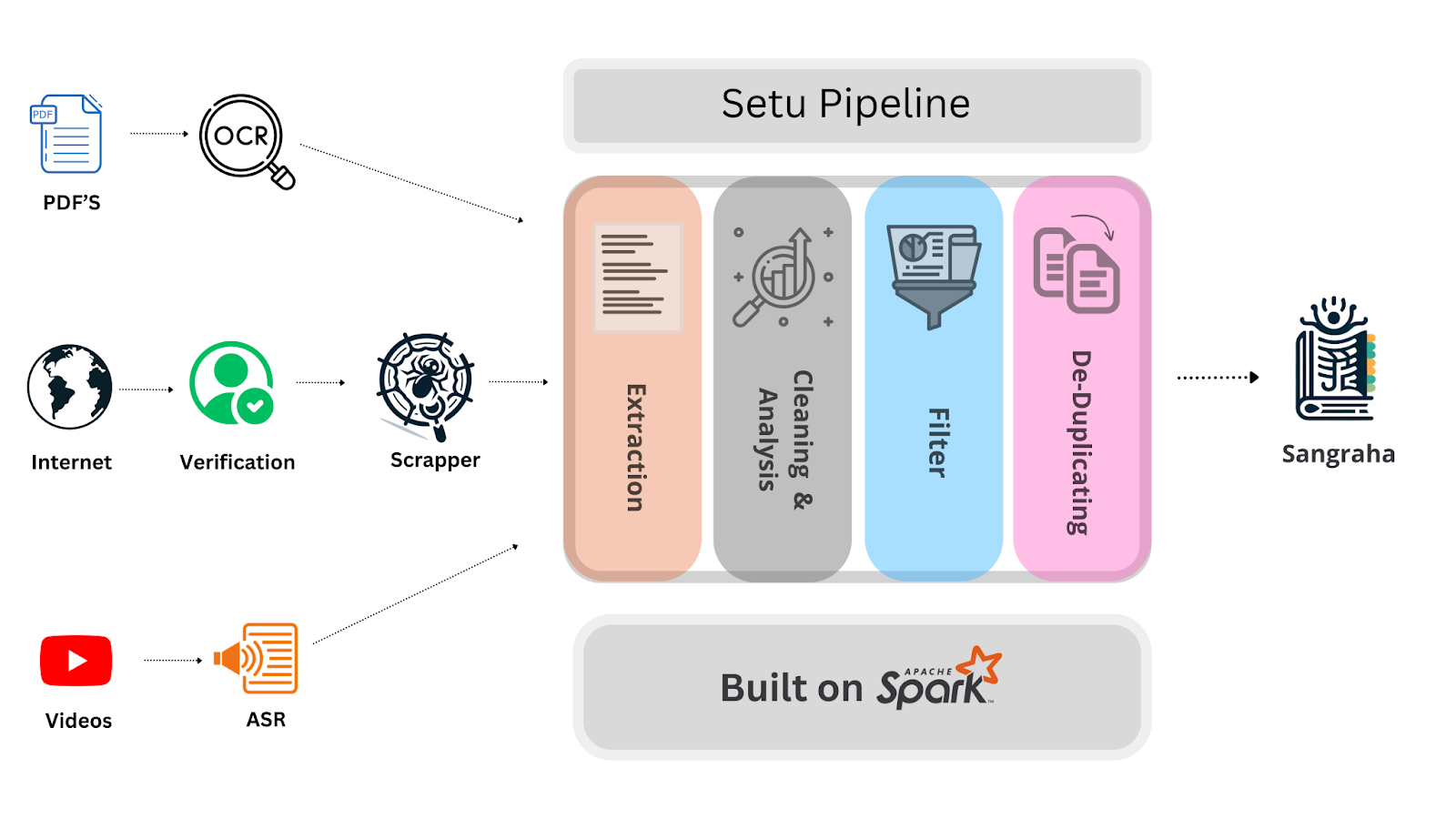
Setu
This is a Spark-based distributed pipeline customized for Indian languages for extracting content from websites, PDFs, and videos. It has in-built stages for cleaning, filtering, toxicity removal, and deduplication.
IndicAlign-Instruct
It offers a varied set of 74.7 million prompt-response pairs in 20 languages.
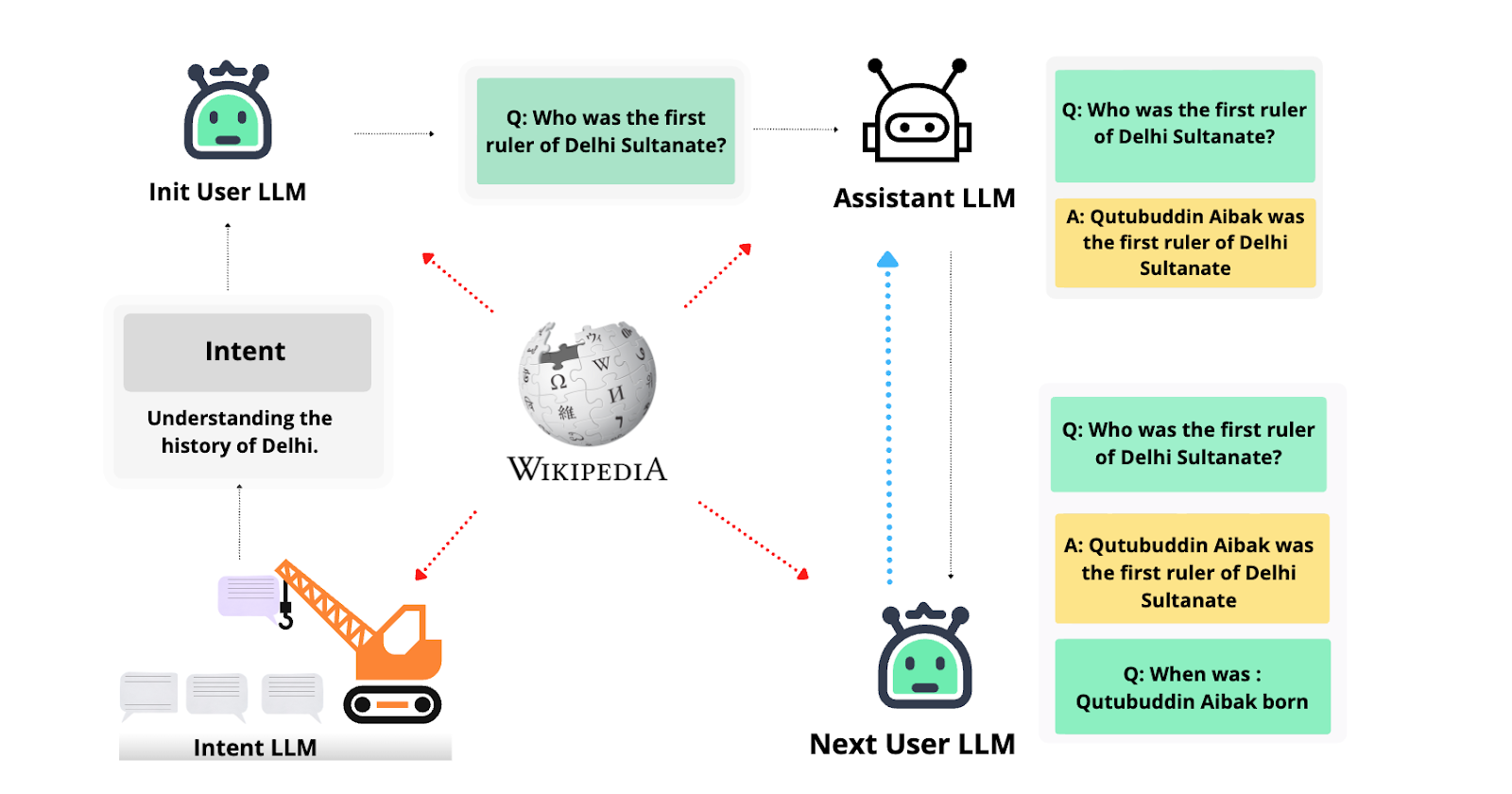
These pairs are gathered using four methods, including compiling existing Instruction Fine-Tuning (IFT) datasets, translating English datasets into 14 Indian languages with an open-source translation model, generating discussions from India-centric Wikipedia articles using open-source LLMs, and setting up a crowdsourcing platform named Anudesh for prompt collection. The team has also introduced a new IFT dataset to teach language and grammar to the model, drawing from IndoWordNet, a resource-rich vocabulary.
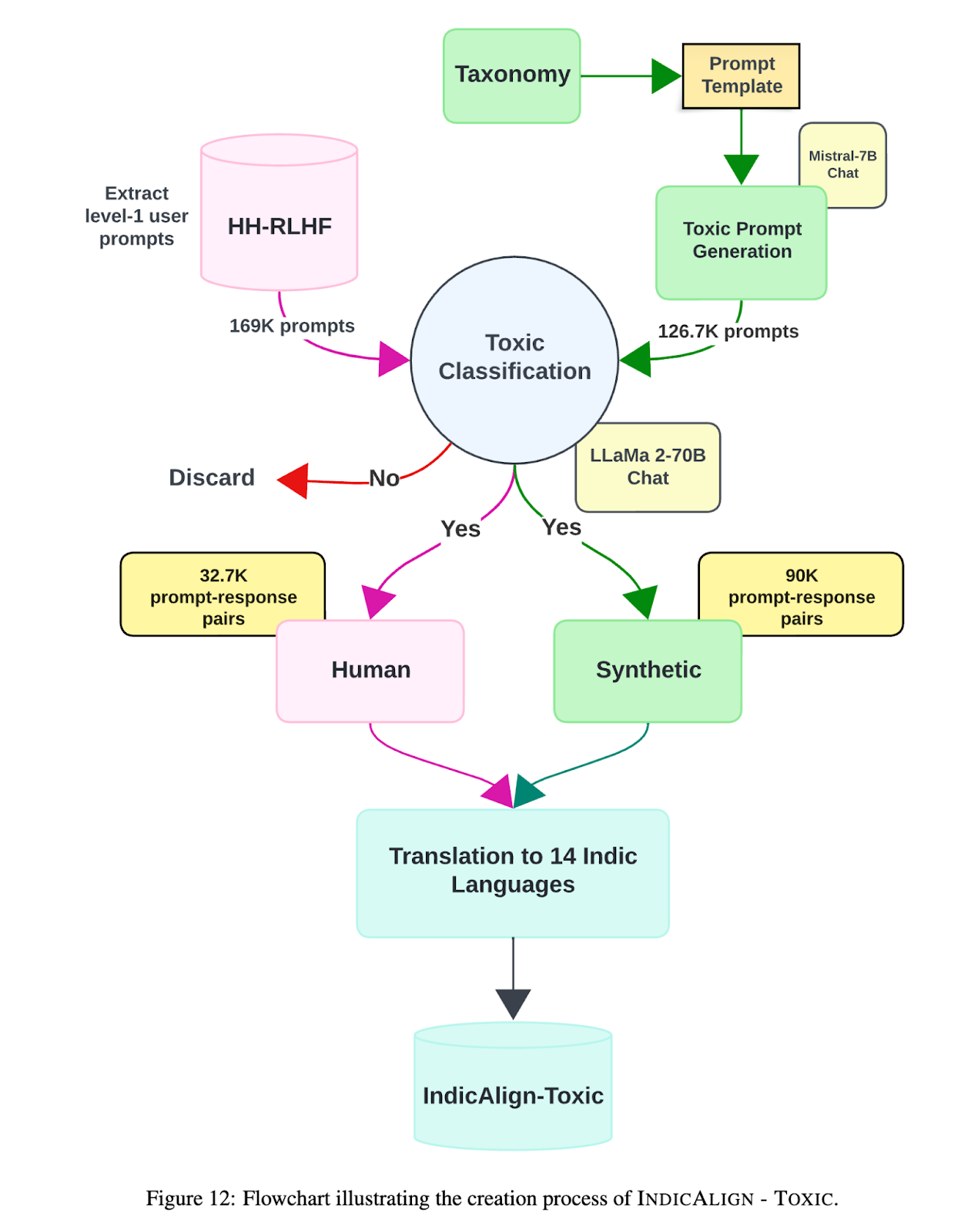
IndicAlign – Toxic
Finally, we have IndicAlign – Toxic, which consists of 123K pairs of toxic prompts and non-toxic responses generated using open-source English LLMs and translated to 14 Indian languages for safety alignment of Indic LLMs.
You can access the data and codes here.
Earlier this month, Sarvam AI, along with AI4Bharat and IIT Madras, unveiled IndicVoices, a comprehensive speech dataset adhering to an inclusive diversity wishlist with fair representation of demographics, domains, languages, and applications. The IndicVoices dataset comprises 7348 hours of natural and spontaneous speech from 16237 speakers across 145 Indian districts and 22 languages.