





|
Listen to this story
|
Every computer nerd wants to control how his data is collected on the internet. Apart from data privacy, there are other reasons for this, such as working in isolated software environments and being less likely to connect to the internet to run LLMs.
Sure, there are lots of open-source LLMs available these days, but they can not be directly accessed. To access, use, and modify them, one would need a platform to work with the data, and that’s where our five options come into play.
AIM tested the listed options with multiple LLMs, checking their performance on three platforms: Linux (Pop!_OS), MacBook M1, and Windows 10, including how they behaved with different LLMs, such as their response time, formatting, and UI.
Ways to Run LLMs Locally on Your Computer
- Jan: Cleanest UI with useful features like system monitoring and LLM library.
- Ollama: Fastest when used on the terminal, and any model can be downloaded with a single command.
- llamafile: The easiest way to run LLM locally on Linux. No additional GUI is required as it is shipped with direct support of llama.cpp.
- GPT4ALL: The fastest GUI platform to run LLMs (6.5 tokens/second).
- LM Studio: Elegant UI with the ability to run every Hugging Face repository (gguf files).
Jan: Plug and Play for Every Platform

While testing, Jan stood out as the only platform with direct support for Ubuntu, as it offers a `.deb` file that can be installed with two clicks, with no terminal interaction required. Furthermore, its user interface is the cleanest among the listed options.
Also, by utilising the LLM, you can access the system monitor, which shows the total CPU and memory consumption. It uses a markdown markup language to output the answer, which means each point is well structured and highlighted, which can be quite helpful when working with programming questions.
You can also choose from a large library of LLMs, including closed-source (which requires API keys to download and use). It also lets you import LLMs, allowing you to easily load manually trained models.
To download/learn more about Jan, visit their GitHub page.
Ollama: The Fastest Way to Run LLMs Locally on Linux

Ollama can be used from the terminal, but if you want to access the GUI, you can use the open web UI (it requires docker). We also tried Ollama on the terminal and GUI, and the response in the terminal was close to how we interact with LLMs over the internet.
This makes it the best option for someone who wants to run LLMs locally on Linux, as most Linux users will be interacting with the terminal. Besides, having access to lightning fast local LLMs directly in the terminal will be great news.

Another good thing about this utility is how it manages dependencies for AMD GPUs automatically on Linux. So, you are not required to download any specific dependencies on your own, it will be taken care of automatically.
Furthermore, you can directly download LLMs with a single command. Also, you can customise the prompt with multiple parameters, such as changing temperature (to balance predictability and creativity), changing system messages, etc. Later on, you can load the custom model for fine-tuned answers.
It worked great when paired with an open web UI, but we encountered a problem when interacting with the terminal.
In the terminal, when you try to load a model, and, for some reason, if it does not load, it won’t show you any error message and show the loading LLM message forever.
It can be tackled by monitoring system resources while loading LLM. If you see a sudden drop in resource utilisation, it means Ollama has stopped loading LLM; you may close the terminal or stop Ollama:

You can visit Ollama’s GitHub page for installation instructions and configuration options.
llamafile: Only Option to Run Huge LLMs Locally on Mid-range Devices
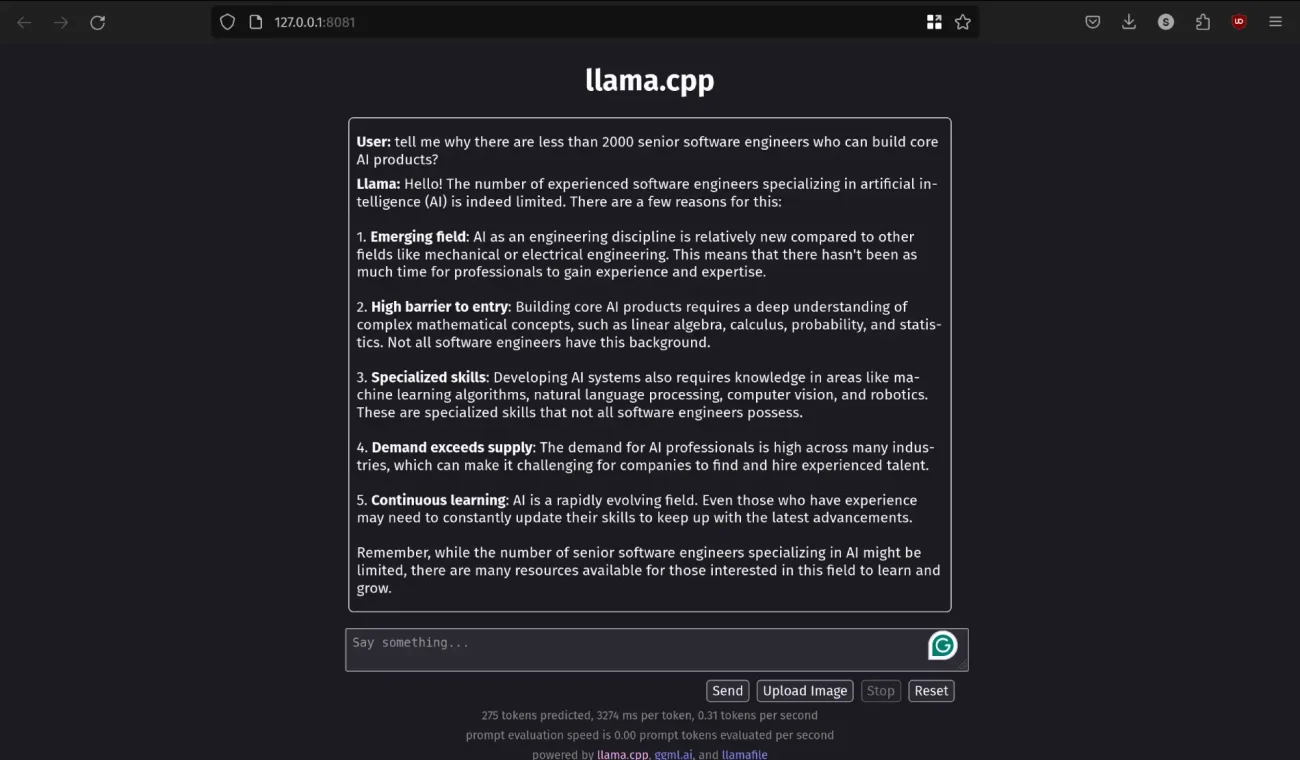
When we started experimenting, llamafile was the only utility that let us use Mistral 70B on our laptop. Sure, it took a long time to generate, but the other options mentioned in the list simply could not load the model itself.
Unlike the other options, you have to download each model from its GitHub repository. This repository can be executed as a script, so you are not required to load the entire model in your RAM before execution.
Also, you are not required to install the GUI platform manually, as it comes backed up with llama.cpp to provide you with a GUI. Besides, it is hosted locally on your browser to minimise resource consumption.
To cater to advanced users, there are many configuration options such as prompt template, temperature, Top-P and K sampling, and advanced options like how many probabilities to show and various Mirostat configuration options.
Visit llamafile’s GitHub page to download the LLM files directly.
GPT4ALL: Fastest Way to Run LLMs Locally on a Computer
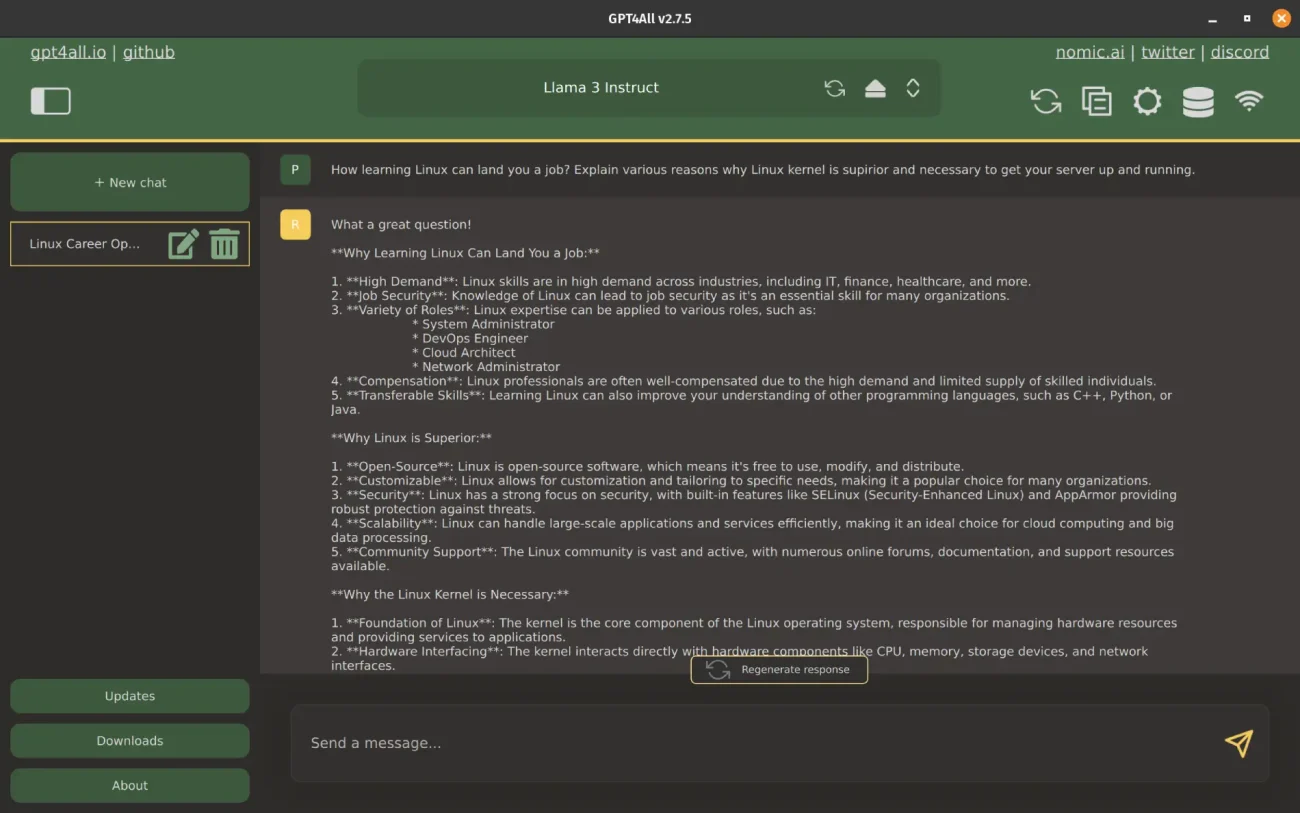
GPT4ALL was the fastest utility in our testing, giving 6.5 tokens/second. We own a mid-range computer, and it is fast for the specs we own. Sure, if you were to pair it with a high-end machine, you’d get better numbers.
Also, they provide an installer for Ubuntu, Mac and Windows for seamless installation, which is a positive thing but for Linux, it does not create a desktop icon, and you end up moving to a specific directory to launch the GPT4ALL.
It has a huge library of LLMs that you can download and run locally. But there was no way to load a locally downloaded model, so you had to rely on their offerings only. Also, it was the only utility on the list that prompts users to share their data and chat responses to improve GPT4ALL.
The only issue that we found is we were not able to use API keys to access the OpenAI GPT-4 model. Also, the user experience is cluttered as developers have added too many options.
Furthermore, the structure of the output was given in a markdown format but printed in plain text, so users end up having markdown symbols in their plain-text outputs.
Visit GPT4ALL’s homepage for further information.
LM Studio: Direct Access to Hugging Face Repository
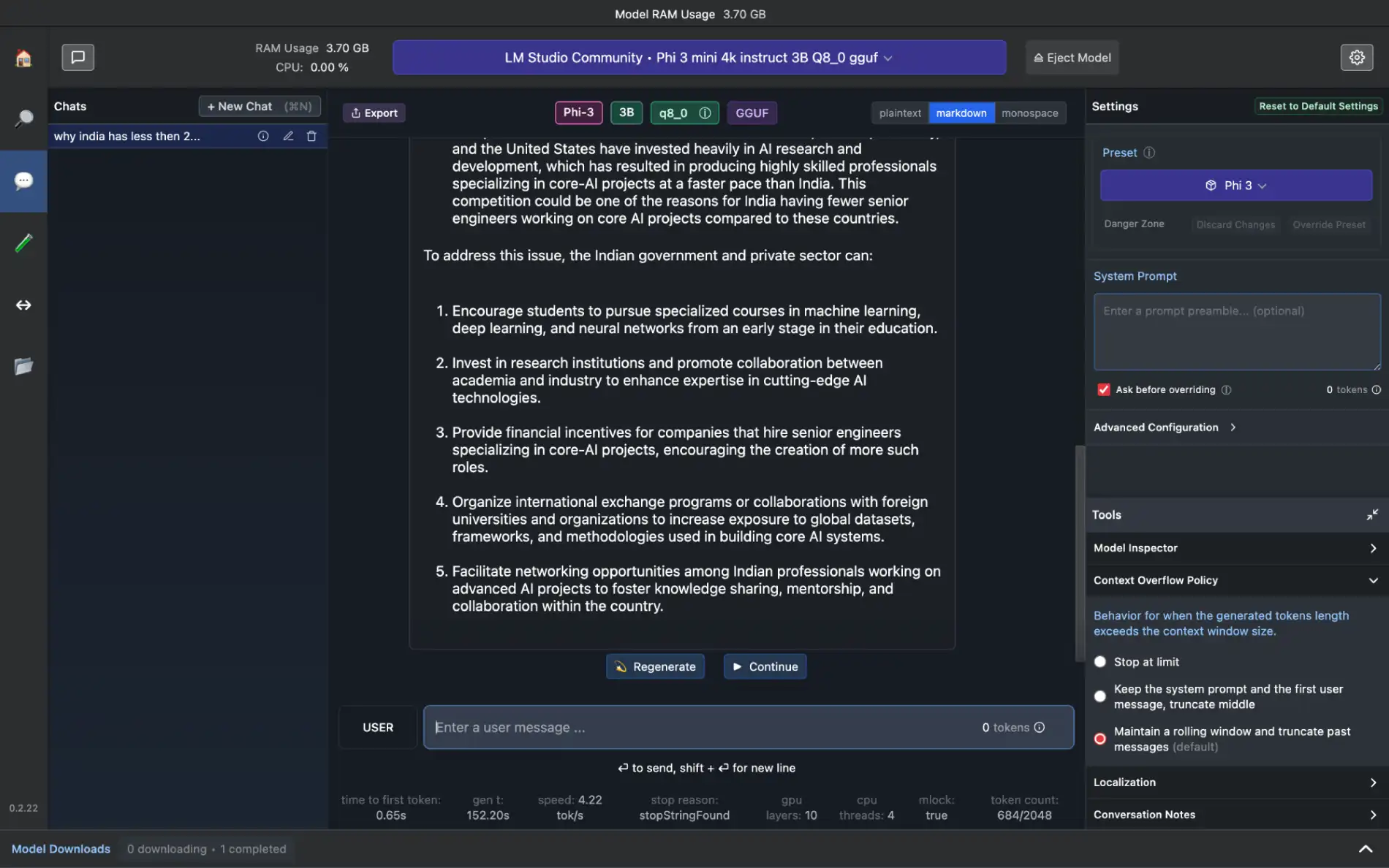
LM Studio was the only utility that did not work on Linux, and struggled to keep up when used on Mac. This means we were only able to use it smoothly on a Windows laptop. However, it can be different if you use different Linux distributions or a higher-spec version of Mac.
The best part is that you can load and prompt multiple LLMs simultaneously with the consult access. Also, you can access any Hugging Face repository within the LM Studio itself, and if not, you can still get the desired LLM from their large library.
Furthermore, you can use locally downloaded/modified LLMs and host an LLM on a local HTTP server.
For further information, visit LM Studio’s official webpage.
Next up, we will explore the possibilities of running LLMs locally on Android/iOS devices to help protect your privacy on the device you use the most – your smartphones.

























