





Anomaly detection is an important part of machine learning that makes the results unbiased to any category or class. While in time series modelling it takes a very important place because there is a variety of anomalies that can be there in time-series data. These anomalies may include seasonal anomalies, regression anomalies, quantile anomalies, etc. ADTK is a toolkit that mainly helps in detecting all types of anomalies. Using this package, we can also perform a variety of procedures that come under time series modelling. In this article, we are going to discuss ADTK with hands-on implementation of anomaly detection. The major points to be discussed in the article are listed below.
Table of Contents
- What is ADTK?
- Implementing anomaly detection with ADTK
- Loading data
- Data preprocessing
- Data validation and visualization
- Seasonal anomaly detection
- Threshold anomaly detection
Let’s start by introducing ADTK.
What is ADTK?
ADTK is an open-source python package for time series anomaly detection. The name ADTK stands for Anomaly detection toolkit. This package is developed by ARUNDO. ARUNDO was founded to solve IoT challenges at the industry level. Talking about the ADTK, its features enable us to implement pragmatic models very easily, and also these features make ADTK different from other anomaly detection tools. The aim behind the development of the ADTK is to promote best practices in solving anomaly detection problems in the real world.
Using this toolkit we can build a rule-based/unsupervised model. Since we barely find anomalous data in historical data and we face problems in building the supervised models and also there is always a requirement to detect anomalies to understand what type of events are of interest. Just by knowing about the rules for those events, we can convert the rules into models using the ADTK. There are three main elements of the ADTK:
- Outlier detector: this element helps in detecting the outliers in the data. There are various modules under this element that help in every type of detection in time series like threshold detection, seasonal detection, regression detection, etc.
- Transformer: These elements help in transforming data. There are various modules under this class like modules for rolling aggregation, seasonal decomposition, etc.
- Rule chain aggregator: These elements help in identifying and aggregating time points set under any rules. We use these functions to aggregate time series using some rules defined by us.
With these elements, this package also provides some other elements for making pipelines, evaluating models, and preprocessing the data. We can install this package using the following lines of codes.
!pip install adtk
After installation, we can use this toolkit for anomaly detection in time series. Let’s see some of the basic things that we can do using ADTK.
Implementing anomaly detection with ADTK
In this section, we will look at the implementation of some modules developed under ADTK packages.
Loading data
Before applying modules we are required to have some time-series data. For this purpose, we are going to use a package named Yfinance to extract share price data from the State Bank of India. Using the below codes we can do that.
import datetime as dt
from datetime import datetime as dt
from dateutil.relativedelta import relativedelta
import yfinance as yf
end = dt.today()
start = dt.today() - relativedelta(years=1)
data = yf.download('SBIN.NS', start, end)
data.tail()
Output:
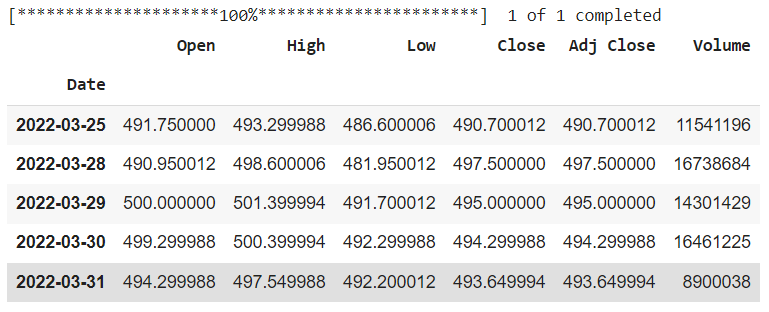
Here we can see that in the data we have share price opening, high, low, and closing, and volume of the share as variables.
Data preprocessing
One thing that is missing with this data is some dates because there are some weekends when the share market does not open. So before going on to the further step we are required to fill this gap but before this, we are required to know how many dates are missing in the data.
pd.date_range(start = start, end = end ).difference(data.index)
Output:

So there are 234 dates missing in two years of data. Here we are going to fill dates with values that accrued on the last date.
idx = pd.date_range(start, end)
data = data.reindex(idx)
data.fillna(method="ffill", inplace = True)Let’s check again if there any dates are missing or not.
pd.date_range(start = start, end = end ).difference(data.index)
Output:
Here we can see that now all the dates are there. Let’s validate the data.
Data validation and visualization
To work with the modules of the ADTK we are required to validate the data with its packages.
from adtk.data import validate_series
data = validate_series(data)
print(data)Output:
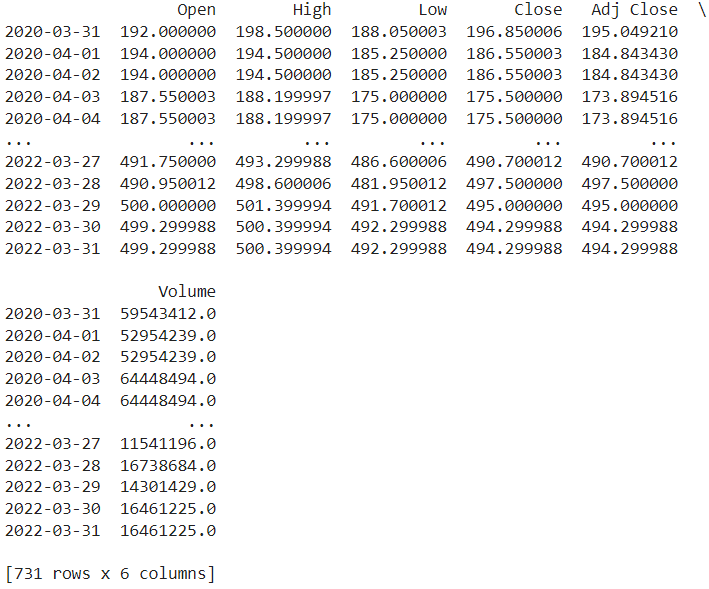
Here we can see our validated data. Let’s plot the data to know how values are varying according to time.
from adtk.visualization import plot
plot(data)
Output:
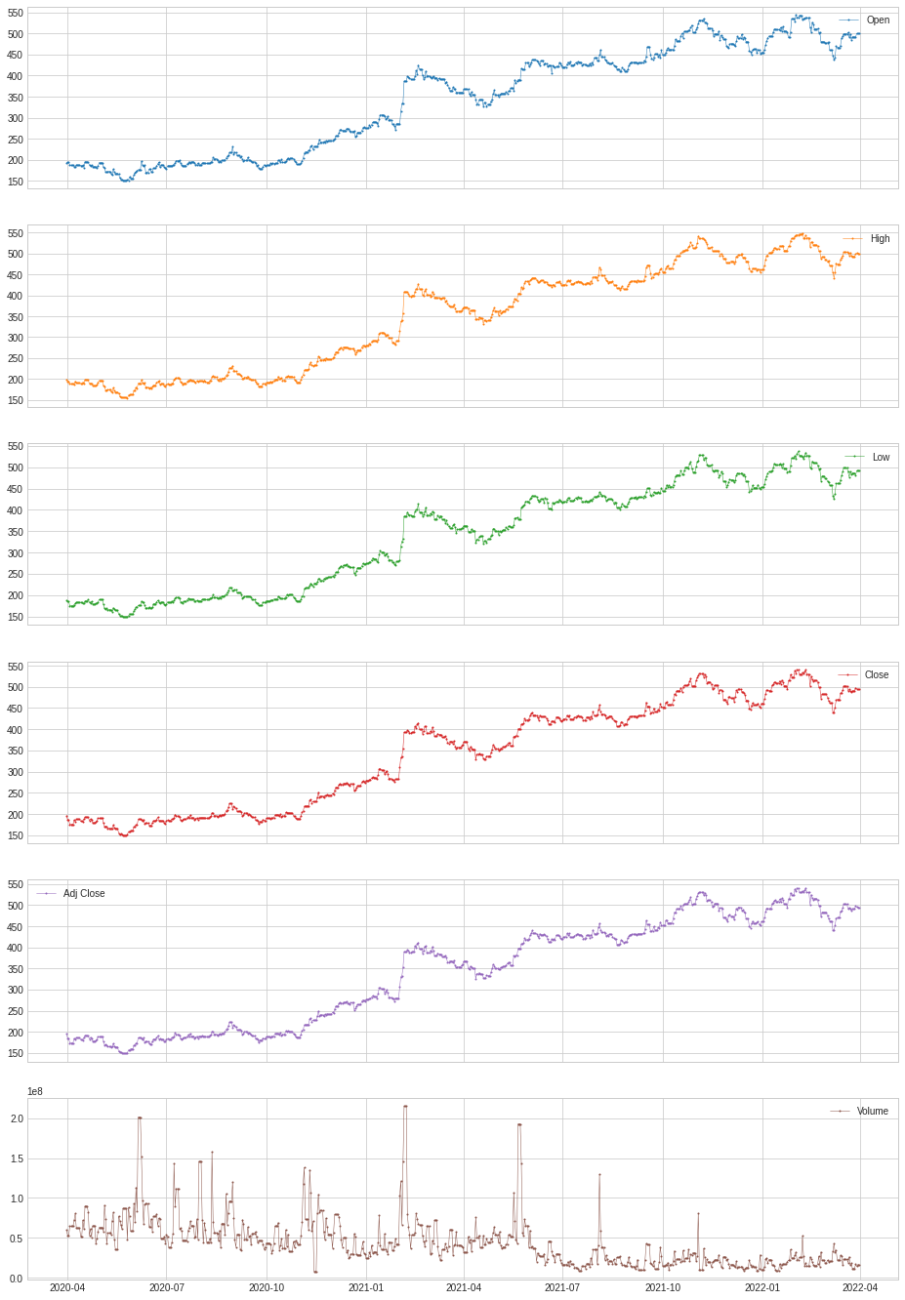
Here we can see full information about the variation in data. And one thing we can easily say is that there are Anomalies in the volume variable.
Seasonal anomaly detection
Let’s just start by detecting violations of seasonal patterns by anomalies and volume variables.
from adtk.detector import SeasonalAD
seasonal_vol = SeasonalAD()
anomalies = seasonal_vol.fit_detect(data['Volume'])
anomalies.value_counts()
Output:

Here we can say in two years there are 19 anomalies that are present in the volume variable. We can also plot this using the following codes.
plot(data, anomaly=anomalies, anomaly_color="orange", anomaly_tag="marker")
Output:
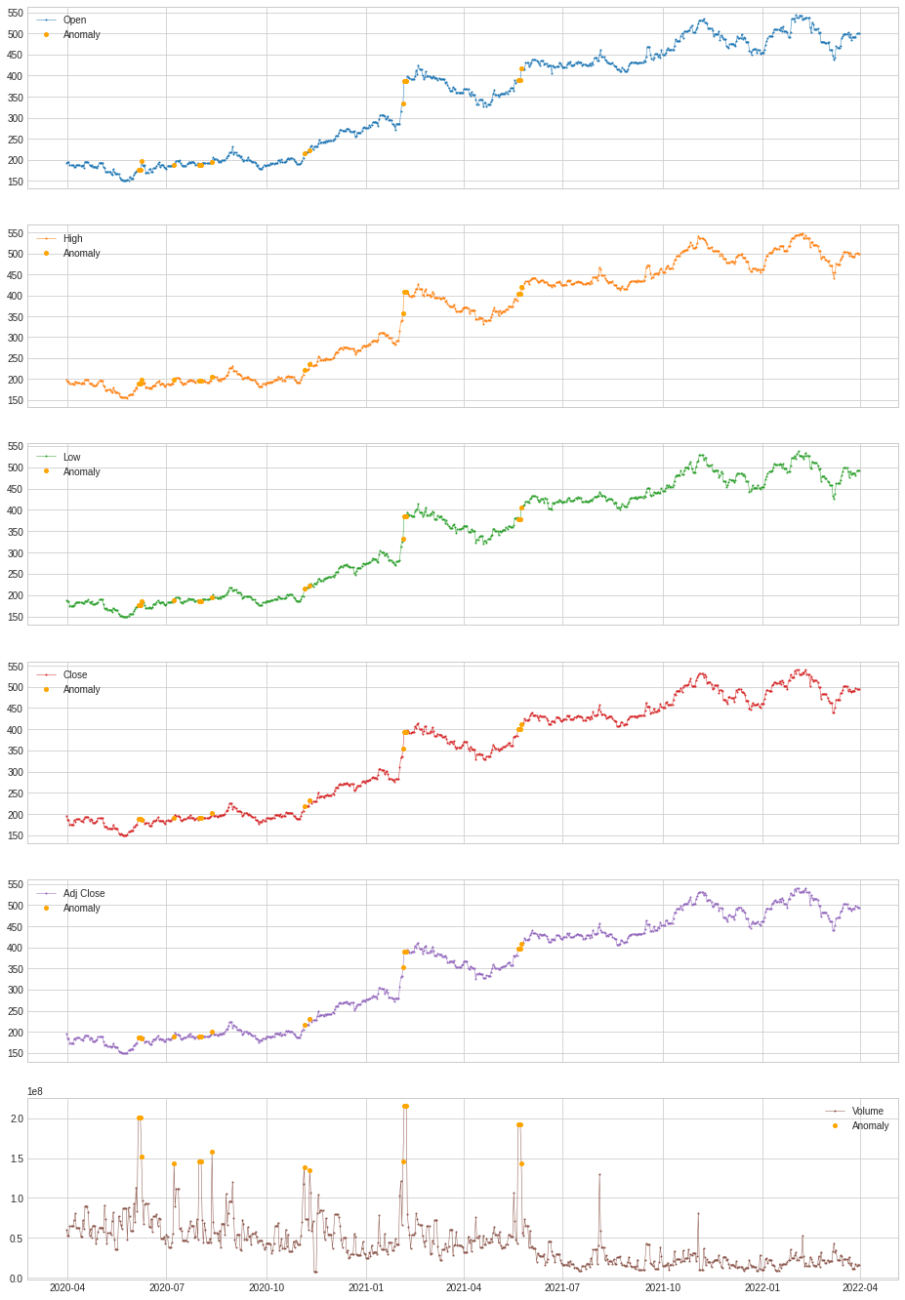
Here we can see where the anomalies of the volume variable are and whether they are affecting the time series or not.
Threshold anomaly detection
We can also define a threshold range and detect points where the time series is going out of this threshold value. Let’s do this for the close column that shows the closing share price of the day.
print('Average closing price', data['Close'].mean())
print('Minimum closing price', data['Close'].min())
print('Maximum closing price',data['Close'].max())Output:
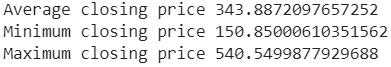
Here we can see what is the average, minimum, TFTand maximum closing prices of the shares. By looking at this we can say values above 530 and below 180 are anomalies and should not be taken in modelling. We can detect these values in the following ways:
from adtk.detector import ThresholdAD
threshold_val = ThresholdAD(high=530, low=180)
anomalies_thresh = threshold_val.detect(data['Close'])Let’s check what are the counts of anomalies are.
anomalies_thresh.value_counts()
Output:

Here we can say there are 65 anomalies. Let’s visualize them.
from adtk.visualization import plot
plot(data, anomaly=anomalies_thresh, ts_linewidth=1, ts_markersize=3, anomaly_markersize=5, anomaly_color='black');Output:

Here we can see the anomalies according to the defined threshold on the closing price of the share. Also, we can check whether these values are affecting the other variable or not.
Final word
In this article, we have discussed the ADTK(anomaly detection toolkit) which has a variety of modules for anomaly detection and modelling in time series. We can find the whole module list here. Along with this, we look at some modules that helped us in detecting anomalies according to seasonal patterns and defined threshold patterns.


























