




AI hardware company Etched has unveiled Sohu, the first specialised chip (ASIC) built exclusively for Transformer models. Today, every major AI product (ChatGPT, Claude, Gemini, Sora) is powered by Transformers and the company believes that within a few years, every large AI model will run on custom chips.
“An accelerator from NVIDIA or Google is flexible. It can be programmed to run many different kinds of AI models, like convolutional networks, TMAs, or Transformers. Our chips are different. They are only able to run this one very narrow class of model, which we call Transformers,” said co-founder and CEO Gavin Uberti.
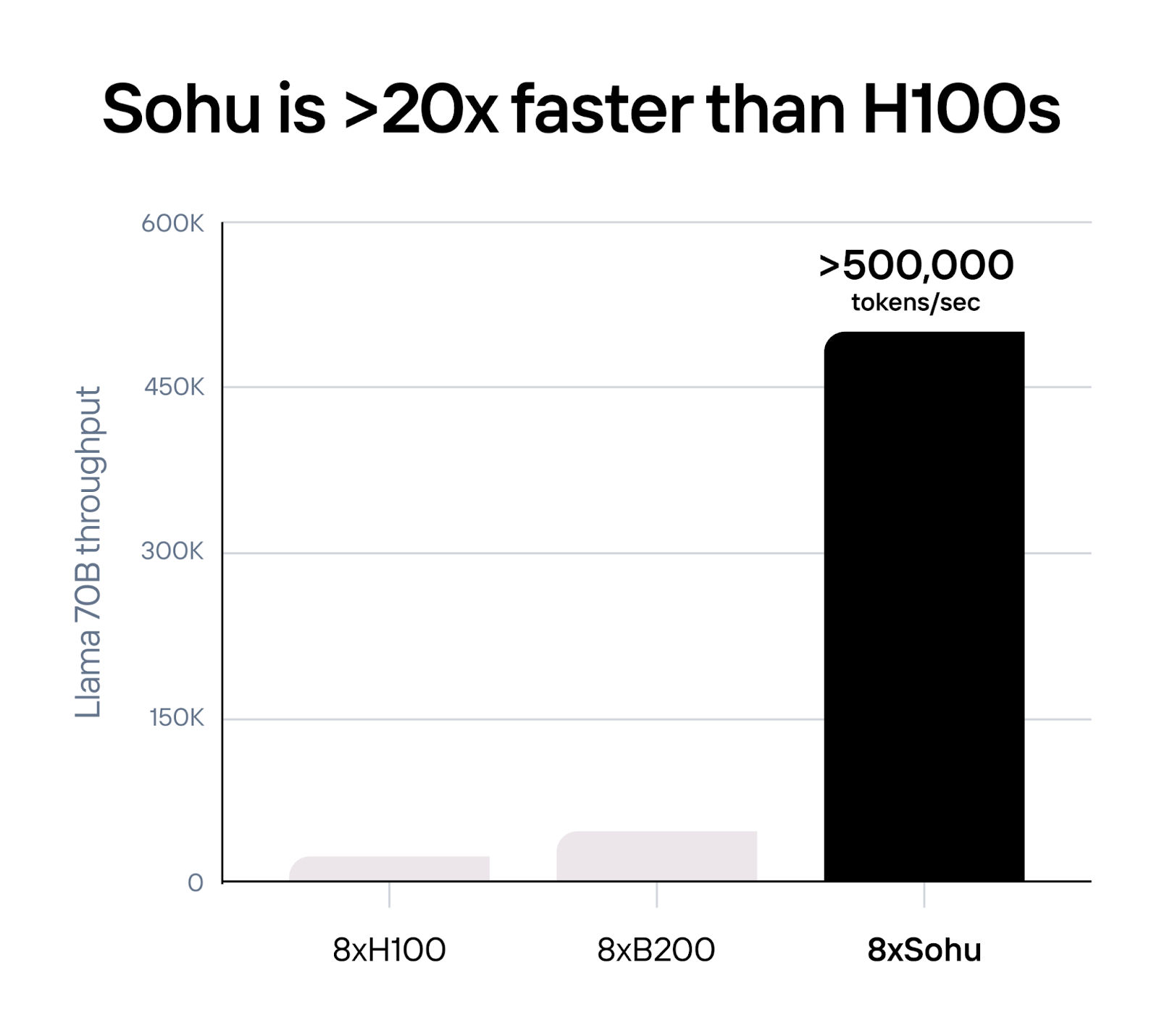
Etched claims that Sohu can process over 500,000 tokens per second with Llama 70B. One 8xSohu server replaces 160 H100s. According to the company, “Sohu is more than 10 times faster and cheaper than even NVIDIA’s next-generation Blackwell (B200) GPUs.”
“We’re able to burn the Transformer algorithm into the chip. We’re building our own silicon and our own servers, and this enables us to get more than 20 times higher throughput in terms of output words per second for models like ChatGPT or Llama,” said Uberti.
Worth the Risk?
Notably, Sohu can’t run CNNs, LSTMs, SSMs, or any other AI models. “If Transformers change dramatically or go away, then we’ll be in a bad place. But if we’re right and Transformers keep being the dominant way that AI models work, we will be the most performant chip in the market by an order of magnitude,” he said.
He added that Sohu can run image and video generation models as well. “I don’t know if you saw Sora from OpenAI, but that’s a Transformer as well,” he said.
On the software side, Etched says that customers don’t need to deal with the hassle of CUDA and PyTorch code, which require incredibly complicated compilers. “However, since Sohu only runs Transformers, we only need to write software for Transformers!” the company said.
Moreover, they assert that “Santa Clara’s dirty little secret is that GPUs haven’t improved, they’ve simply grown larger”. Uberti said that next-gen GPUs (NVIDIA B200, AMD MI300X, Intel Gaudi 3, AWS Trainium2, etc.) now count two chips as one card to “double” their performance.
Etched was founded by Harvard dropouts Uberti and Chris Zhu, both of whom have a background in AI and hardware development. They recently raised $120 million in a Series A funding round, bringing their total funding to $125.4 million. Notable investors include Peter Thiel, Thomas Dohmke (the CEO of GitHub), and Balaji Srinivasan (former CTO at Coinbase).
NVIDIA is Not the Only One
While NVIDIA maintains a dominant 95% share of the AI chip market, new competitors are fast emerging. Groq, like Etched, is gaining traction with its LPUs. Groq has demonstrated impressive performance, achieving throughput of 877 tokens/s on Llama 3 8B and 284 tokens/s on Llama 3 70B. A user on X compared Llama 3 (on Groq) and GPT-4 by tasking them with coding a snake game in Python, where Groq performed exceptionally fast.
In addition to Groq, major tech giants like Microsoft, Google, and Amazon are also advancing their own AI chips. Last year, Microsoft introduced Azure Maia 100 AI Accelerator, built for AI tasks and generative AI workloads in cloud computing environments.
Amazon has also entered the fray with its Tranium2 and Inferentia chips, designed specifically for training AI models such as ChatGPT and its competitors. Startups like Databricks and Anthropic use Amazon’s Trainium2 chips to develop their models. Reportedly, Amazon is currently building its own ChatGPT-like model.
Google has been developing custom AI accelerator chips called Tensor Processing Units (TPUs) since 2015. At Google I/O 2024, the search giant unveiled its 6th generation Tensor Processing Units, called Trillium, delivering a 4.7x performance boost over its predecessor.
Will the Transformer Stay for Long?
The success of Etched is dependent on Transformers.
However, recently, Cohere founder Aidan Gomez and one of the authors of paper, ‘Attention is all you Need’ expressed his dissatisfaction with the current state of AI developments, all of which are built on top of Transformers.
“It kind of disturbs me how similar to the original form we are. I think the world needs something better than the Transformer,” he said.
Nonetheless, researchers challenging Transformers is not new. The latest paper by Sepp Hochreiter, the inventor of LSTM, has unveiled a new LLM architecture featuring a significant innovation: xLSTM, which stands for Extended Long Short-Term Memory.
In December last year, researchers Albert Gu and Tri Dao from Carnegie Mellon and Together AI introduced Mamba, a state-space model (SSM) that demonstrates superior performance across various modalities, including language, audio, and genomics.
In April, Google also unveiled a new family of open-weight language models, RecurrentGemma 2B, by Google DeepMind, based on the novel Griffin architecture.
Etched can only hope that Transformers are here to stay in the long run.


















