





|
Listen to this story
|
If we are providing a huge dataset to the model to learn, it is possible that a few important parts of the data might be ignored by the models. Paying attention to important information is necessary and it can improve the performance of the model. This can be achieved by adding an additional attention feature to the models. Neural networks built using different layers can easily incorporate this feature through one of the layers. We can use the attention layer in its architecture to improve its performance. In this article, we are going to discuss the attention layer in neural networks and we understand its significance and how it can be added to the network practically. The major points that we will discuss here are listed below.
Table of contents
Problem with Neural Networks
In many of the cases, we see that the traditional neural networks are not capable of holding and working on long and large information. Let’s talk about the seq2seq models which are also a kind of neural network and are well known for language modelling. More formally we can say that the seq2seq models are designed to perform the transformation of sequential information into sequential information and both of the information can be of arbitrary form. A simple example of the task given to the seq2seq model can be a translation of text or audio information into other languages.

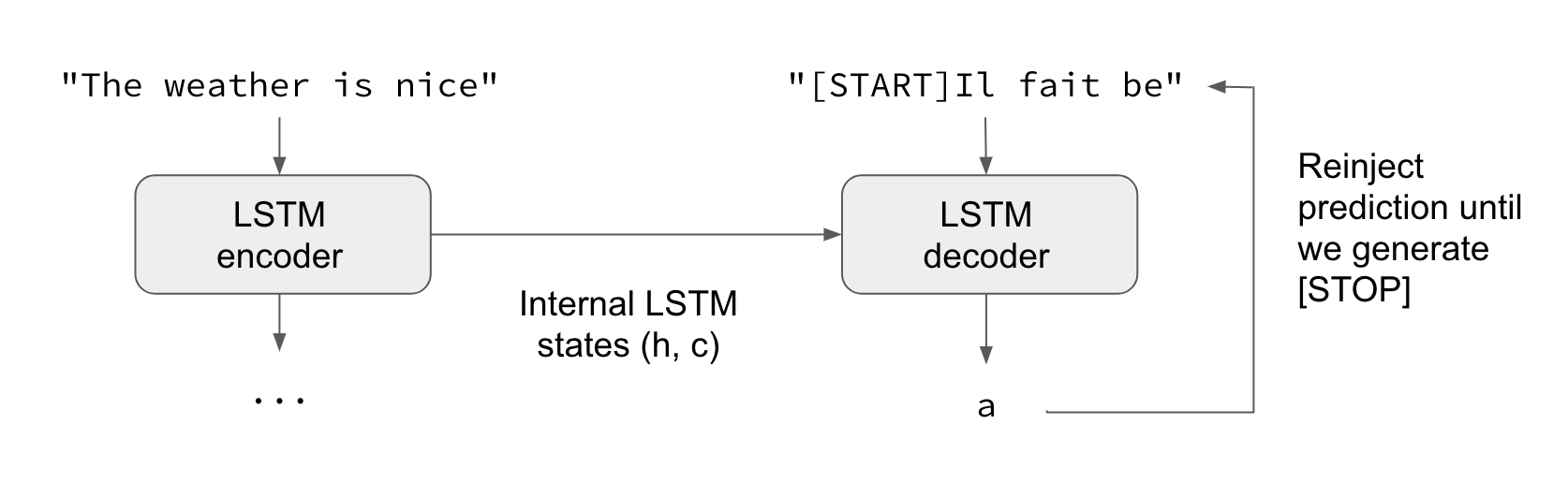
The above image is a representation of a seq2seq model where LSTM encode and LSTM decoder are used to translate the sentences from the English language into French. So we can say in the architecture of this network, we have an encoder and a decoder which can also be a neural network.
When we talk about the work of the encoder, we can say that it modifies the sequential information into an embedding which can also be called a context vector of a fixed length. A critical disadvantage with the context vector of fixed length design is that the network becomes incapable of remembering the large sentences. We can often face the problem of forgetting the starting part of the sequence after processing the whole sequence of information or we can consider it as the sentence. So providing a proper attention mechanism to the network, we can resolve the issue.
What is an Attention Mechanism?
A mechanism that can help a neural network to memorize long sequences of the information or data can be considered as the attention mechanism and broadly it is used in the case of Neural machine translation(NMT). As we have discussed in the above section, the encoder compresses the sequential input and processes the input in the form of a context vector. We can introduce an attention mechanism to create a shortcut between the entire input and the context vector where the weights of the shortcut connection can be changeable for every output.
Because of the connection between input and context vector, the context vector can have access to the entire input, and the problem of forgetting long sequences can be resolved to an extent. Using the attention mechanism in a network, a context vector can have the following information:
- Encoder hidden states;
- Decoder hidden states;
- Alignment between source and target.
Using the above-given information, the context vector will be more responsible for performing more accurately by reducing the bugs on the transformed data.

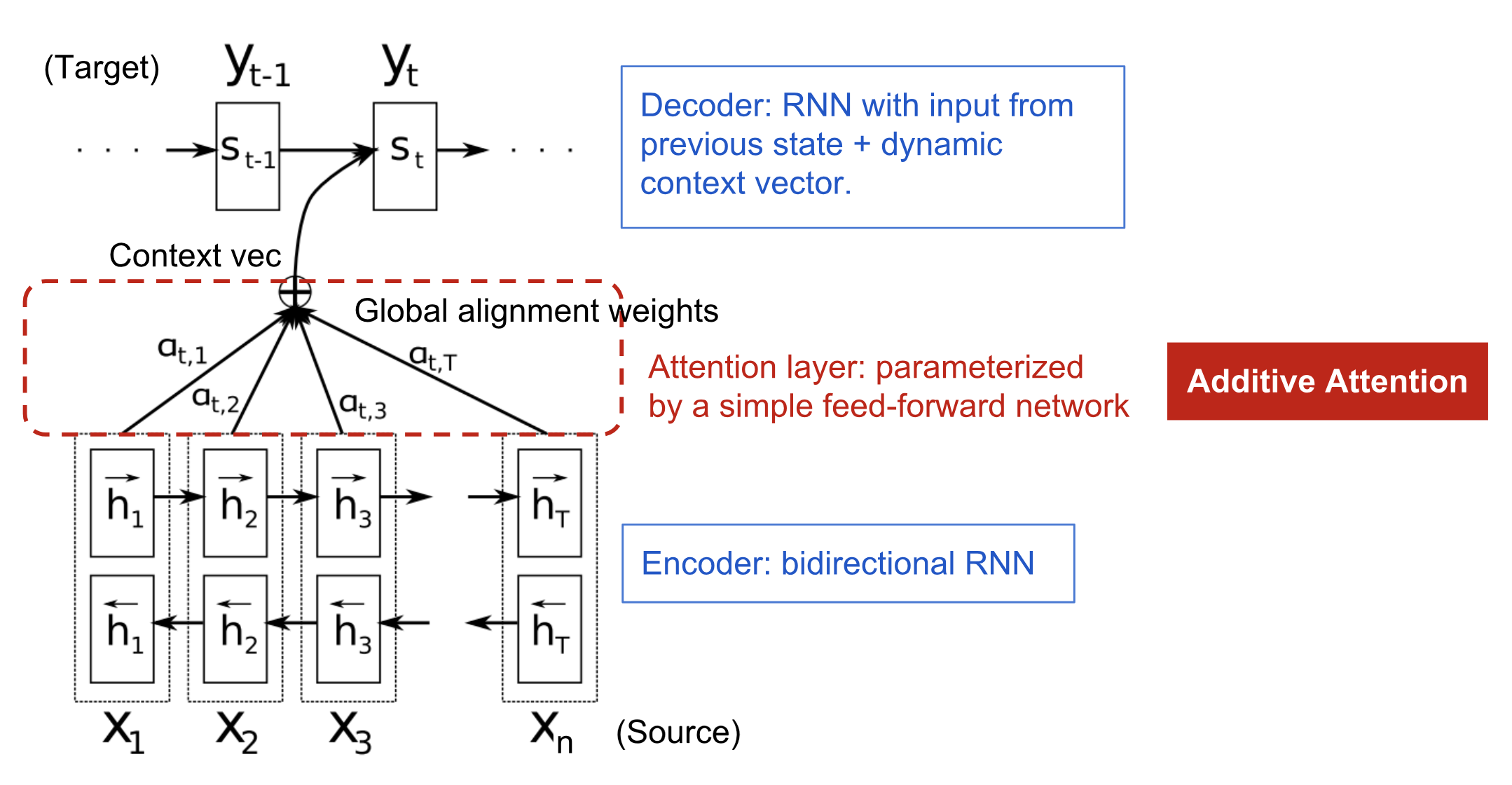
The above given image is a representation of the seq2seq model with an additive attention mechanism integrated into it. Let’s introduce the attention mechanism mathematically so that it will have a clearer view in front of us. Let’s say that we have an input with n sequences and output y with m sequence in a network.
x = [x1, x2,…, xn]
y = [y1, y2,…, ym]
Now the encoder which we are using in the network is a bidirectional LSTM network where it has a forward hidden state and a backward hidden state. Representation of the encoder state can be done by concatenation of these forward and backward states.

Where in the decoder network, the hidden state is

For the output word at position t, the context vector Ct can be the sum of the hidden states of the input sequence.

Here we can see that the sum of the hidden state is weighted by the alignment scores. We can say that {αt,i} are the weights that are responsible for defining how much of each source’s hidden state should be taken into consideration for each output.
There can be various types of alignment scores according to their geometry. It can be either linear or in the curve geometry. Below are some of the popular attention mechanisms:

They have different alignment score functions. Also, we can categorize the attention mechanism into the following ways:
- Self-Attention
- Global/Soft
- Local/Hard
Let’s have an introduction to the categories of the attention mechanism.
Self-Attention Mechanism
When an attention mechanism is applied to the network so that it can relate to different positions of a single sequence and can compute the representation of the same sequence, it can be considered as self-attention and it can also be known as intra-attention. In the paper about. Long Short-Term Memory-Networks for Machine Reading by Jianpeng Cheng, Li Dong, and Mirella Lapata, we can see the uses of self-attention mechanisms in an LSTM network. The below image is a representation of the model result where the machine is reading the sentences.

Here in the image, the red color represents the word which is currently learning and the blue color is of the memory, and the intensity of the color represents the degree of memory activation.
As of now, we have seen the attention mechanism, and when talking about the degree of the attention is applied to the data, the soft and hard attention mechanism comes into the picture, which can be defined as the following.
Soft/Global Attention Mechanism
When the attention applied in the network is to learn, every patch or sequence of the data can be called a Soft/global attention mechanism. This attention can be used in the field of image processing and language processing.
For image processing, the same kind of attention is applied in the Neural Machine Translation by Jointly Learning to Align and Translate paper created by Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio.
Local/Hard Attention Mechanism
when the attention mechanism is applied to some patches or sequences of the data, it can be considered as the Local/Hard attention mechanism. This type of attention is mainly applied to the network working with the image processing task.
The paper, Effective Approaches to Attention-based Neural Machine Translation by Minh-Thang Luong, Hieu Pham, and Christopher D. Manning, represents the example of applying global and local attention in a neural network works for the translation of the sentences.

The above image is a representation of the global vs local attention mechanism. Let’s go through the implementation of the attention mechanism using python.
Implementation
When talking about the implementation of the attention mechanism in the neural network, we can perform it in various ways. One of the ways can be found in the article. Where we can see how the attention mechanism can be applied into a Bi-directional LSTM neural network with a comparison between the accuracies of models where one model is simply bidirectional LSTM and other model is bidirectional LSTM with attention mechanism and the mechanism is introduced to the network is defined by a function.
We can also approach the attention mechanism using the Keras provided attention layer. The following lines of codes are examples of importing and applying an attention layer using the Keras and the TensorFlow can be used as a backend.
from tensorflow import keras
from keras import layers
layers.Attention(
use_scale=False, **kwargs
)Here, the above-provided attention layer is a Dot-product attention mechanism. We can use the layer in the convolutional neural network in the following way.
Before applying an attention layer in the model, we are required to follow some mandatory steps like defining the shape of the input sequence using the input layer.
query = keras.Input(shape=(None,), dtype='int32')
value = keras.Input(shape=(None,), dtype='int32')As an input, the attention layer takes the Query Tensor of shape [batch_size, Tq, dim] and value tensor of shape [batch_size, Tv, dim], which we have defined above. Now we can make embedding using the tensor of the same shape.
token_embedding = layers.Embedding(input_dim=1000, output_dim=64)
query_embeddings = token_embedding(query)
value_embeddings = token_embedding(value)Now we can define a convolutional layer using the modules provided by the Keras.
layer_cnn = layers.Conv1D(filters=100, kernel_size=4, padding='same')
Here the argument padding is set as the same so that the embedding we are sending as input can remain the same after the convolutional layer.
Now we can fit the embeddings into the convolutional layer.
query_encoding = layer_cnn(query_embeddings)
value_encoding = layer_cnn(value_embeddings)Now we can add the encodings to the attention layer provided by the layers module of Keras.
query_attention_seq = layers.Attention()([query_encoding, value_encoding])
Till now, we have taken care of the shape of the embedding so that we can put the required shape in the attention layer. Now if required, we can use a pooling layer so that we can change the shape of the embeddings,
query_encoding = layers.GlobalAveragePooling1D()(query_encoding)
query_value_attention = layers.GlobalAveragePooling1D()(query_attention_seq)After adding the attention layer, we can make a DNN input layer by concatenating the query and document embedding.
input_layer = tf.keras.layers.Concatenate()([query_encoding, query_value_attention])
After all, we can add more layers and connect them to a model.
Final Words
Here in the article, we have seen some of the critical problems with the traditional neural network, which can be resolved using the attention layer in the network. Along with this, we have seen categories of attention layers with some examples where different types of attention mechanisms are applied to produce better results and how they can be applied to the network using the Keras in python. I encourage readers to check the article, where we can see the overall implementation of the attention layer in the bidirectional LSTM with an explanation of bidirectional LSTM.
References



























{kind=link}
{kind=link}