





To make the predictive models more robust and outperforming, we need to use those modules and processes that are lightweight and can work faster. Ktrain is a lightweight python wrapper that provides such features to an extent. It is a lightweight wrapper for the deep learning library TensorFlow Keras that helps in building, training, and deploying neural networks and other machine learning models. In this article, we are going to discuss the ktrain package in detail. We will go through its important features and pre-trained models available with it. Along with that, we also implement a BERT model available with ktrain for a text classification problem. The major points to be discussed in the article are listed below.
Table of Contents
- About ktrain
- Models Available with ktrain
- Important Features of ktrain
- How to Install ktrain?
- Text Classification using BERT with ktrain
- Real-Life Application of ktrain
About ktrain
As we have discussed problems associated with high weight modules, ktrain can be a solution to this problem for us which is a lightweight wrapper library like TensorFlow Keras. It can be very helpful in building projects consisting of neural networks. Using this wrapper, we can build, train and deploy deep learning and machine learning models. The main inspiration behind building this wrapper is machine learning frameworks like fastai and Ludwig. The inspiration behind the design of ktrain is to make deep learning and artificial intelligence more accessible and easier for any type of user, either beginners or experienced.
Models Available with ktrain
This wrapper can be used for employing pre-trained, fast, and easy to use models that can be applied to text data, computer vision problems, graphs, and tabular data. Let’s have a look at the list of models for the different categories of data and problems.
NLP Problems with Text Data
- Classification: BERT, DistilBERT, NBSVM, fastText etc.
- Regression: BERT, DistilBERT, fastText, and linear text regression using embeddings.
- Unsupervised learning: LDA.
Also, we have different models for Named Entity Recognition and pairing. There are various models available in the wrapper which can be used in various tasks of natural language processing where the text data can be used.
Computer Vision Problems
- Image Classification: ResNet, Wide ResNet, Inception etc.
- Image regression: EesNet50, MobileNet, inception etc.
Modelling with Graphical Data
For this kind of data, we have graph neural networks like GraphSAGE network for node classification and link prediction in the wrapper.
Tabular Data
In the section of tabular data also, we have various statistical models available which can be used for classification, regression, and causal inferences. These are some of the basic facilities which are required to be provided by this kind of wrapper. Instead of this, there are some other external facilities available with this wrapper.
Important Features of ktrain
Some of the major external facilities from the wrapper to the modeller are listed below:
- Using the wrapper’s learning rate finder, we can estimate the model’s optimal learning rate fitted on the data.
- The wrapper provides various learning rate schedules such as triangular policy and SGDR to improve the generalization and decrease the losses on the modelling.
- Using the wrapper, we can easily build classification models for the text data of any language.
- We can easily train named entity recognition models for any language.
- We have facilities for pre-processing and inspection of the data.
- We can also save modelling and preprocessing procedures so that a similar method can be used for the upcoming new data.
- We can export models made on ktrain to TensorFlow lite and ONNX. It means we also have compatibility with some of the libraries in the wrapper.
Here we have seen what are the other features we have got from the wrapper which can be used to make the modelling experience more improved and better. Now we can proceed further in the article where we will discuss the installation procedure of the wrapper.
How to Install ktrain?
As we could understand, ktrain is a lightweight wrapper for deep learning modelling that can be used in place of libraries like TensorFlow and Keras. Before using the wrapper for modelling, we are required to install it in our environment. Since I am using Google Colab for modelling, I will let you go through how we can install and use it in the Google Colab environment.
We can install the wrapper using the following line of codes:
!pip install ktrain
Output :
Here the installation of the wrapper will take some time. After installation, we can check for the version of the ktrain using the following codes.
ktrain.__version__
Output:

Some of the basic requirements for installing ktrain are that we should have up-to-date pip installed in the environment. Also, we are required to have TensorFlow installed in the environment. Now we are ready to use the library on the notebook where we have installed the ktrain.
Text Classification using BERT with ktrain
In this section of the article, we are going to see how we can use any pre-trained model using the ktrain wrapper as the backend of the process.
For the above-given purpose, we are going to perform text classification on the 20_news_group dataset. This dataset can be imported from sklearn.dataset library lets start our procedure by calling the data set.
# fetch the dataset using scikit-learn
category = ['alt.atheism', 'soc.religion.christian',
'comp.graphics', 'sci.med']
from sklearn.datasets import fetch_20newsgroups
train, test = fetch_20newsgroups(subset='train',
categories=category, shuffle=True, random_state=42),fetch_20newsgroups(subset='test',
categories=category, shuffle=True, random_state=42)
print('size of training set: %s' % (len(train['data'])))
print('size of validation set: %s' % (len(test['data'])))
x_train = train.data
y_train = train.target
x_test = test.data
y_test = test.targetOutput:

As we have discussed before, we are provided with the facility of loading and preprocessing the data in the wrapper. Since the data we have is text data so in the modelling we are going to use the text from the ktrain. Also, as we have the data is in the form of an array, we can use module text_from_array to load it and preprocess it according to the BERT model.
# import ktrain and the ktrain.text modules
import ktrain
from ktrain import text
(x_train, y_train), (x_test, y_test), preproc = text.texts_from_array(x_train=x_train, y_train=y_train,x_test=x_test, y_test=y_test,class_names=train_b.target_names,
preprocess_mode='bert',maxlen=350, max_features=35000)Output:

Now after loading the data and preprocessing it, we can load our model and can create an instance of it that can be used for learning the model.
model = text.text_classifier('bert', train_data=(x_train, y_train), preproc=preproc)
learner = ktrain.get_learner(model, train_data=(x_train, y_train), batch_size=6)Output :

As we have discussed in the features, we can use various learning rate schedules using the ktrain and because it is suggested to use any of the learning rates from 5e-5, 3e-5, or 2e-5 for the BERT model, we are using 2e-5 for the training of the model with one cycle learning rate policy.
learner.fit_onecycle(2e-5, 4)
Output:

Here in the metrics section, we can see the accuracy score in the training which is quite satisfactory and also took less time to get trained. To cross-check the model with the test data, we can use the validate method assigned to the learner instance of the model.
learner.validate(val_data=(x_test, y_test), class_names=train.target_names)
Output :
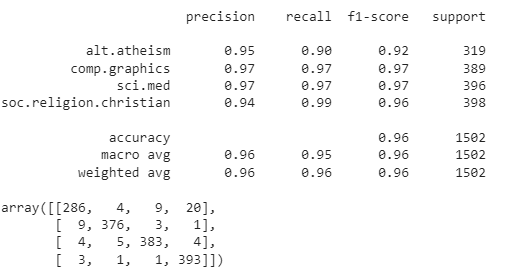
Here in the output, we can see that we have got an accuracy of 96%. That is also a satisfactory result by the model. Here we have seen that using the BERT model for text classification on the 20_news_group dataset, we have achieved a higher accuracy on the testing where the ktrain wrapper is used as the backend.
Real-Life Application of ktrain
In recent years the whole world has been facing problems occurring due to the COVID pandemic and the whole world is trying to figure out the solution to it. In July 2021, news came out related to ktrain and COVID, where Stanford university was using a machine-learning-enhanced search engine for COVID publications. The search engine was made using the ktrain wrapper. This resulted in the generation of the CoronaBERT model which is a classifier of the CoronaCentral document and available on the ktrain’s hugging face model hub. CoronaCentral.ai was developed by Jake Lever and Russ Altman and funded by the Chan Zuckerberg Biohub.
Final Words
Here in this article, we had an overview of the ktrain lightweight wrapper for TensorFlow Keras which helps in developing the deep learning model easily. Since it is open-source, it makes the models more accessible to everyone. Along with that, we have seen how we can use it for our works with a lower amount of codes. In this article, we could perform most of the tasks of modelling using the wrapper only.
References


























