





In natural language processing, we are required to perform various types of text preprocessing tasks so that the mathematical operations can be performed on the data. Before applying mathematics to such data, data is required to be represented in the mathematical format. For text data, the term-document matrix is a kind of representation that helps in converting text data into mathematical matrices. In this article, we are going to discuss the term-document matrix and we will see how we can make one. We will do a hands-on implementation of term-document matrices in R and Python programming languages for a better understanding. The major points to be discussed in this article are listed below.
Table of Contents
- What is a Term-Document Matrix?
- Term-Document Matrix in R
- Term-Document Matrix in Python
- Using Pandas
- Using Text Mining
- Application of Term-Document Matrix
Let’s start the discussion by understanding what the term-document matrix is.
What is a Term-Document Matrix?
In natural language processing, we see many methods of representing text data. Term document matrix is also a method for representing the text data. In this method, the text data is represented in the form of a matrix. The rows of the matrix represent the sentences from the data which needs to be analyzed and the columns of the matrix represent the word. The dice under the matrix represent the number of occurrences of the words. Let’s understand it with an example.
| Index | Sentences |
| 1 | I love football |
| 2 | Messi is a great football player |
| 3 | Messi has won seven Ballon d’Or awards |
Here, we can see a set of text responses. The term-document matrix of these responses will look like this:
| I | love | football | Messi | is | a | great | player | has | won | seven | Ballon d’Or | awards | |
| I love football | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Messi is a great football player | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| Messi has won seven Ballon d’Or awards | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
The above table is a representation of the term-document matrix. From this matrix, we can get the total number of occurrences of any word in the whole corpus and by analyzing them we can reach many fruitful results. Term document matrices are one of the most common approaches which need to be followed during natural language processing and analyzing the text data. More formally we can say that it is the way to represent the relationship between words and sentences presented in the corpus.
Since R and python are two common languages that are being used for the NLP, we are going to see how we can implement a term-document matrix in both of the languages. Let’s start with the R language.
Implementation in R
In this section of the article, we are going to see how we can create a term-document matrix using the R language. For this purpose, we are required to install the tm(text mining) library in our environment.
Installing library:
install.packages("tm")
Using the above lines of codes, we can install the text mining library. Instead of term-document and document-term matrix, we have various facilities available in the library from the field of text mining and others.
Importing the library:
library(tm)
Using the above lines of code we can call the library.
Importing data:
For making a term-document matrix in R, we are using crude data which comes with the tm library and it is a volatile corpus of 20 news articles which are dealing with crude oil.
data("crude")
Lets inspect the crude vcorpus
inspect(crude[1:2])
Output:

Here is the output. We can see the character counts and metadata information in vcorpu. For more detailed information, we can use the help function of the R.
help(crude)
Output:

Here we can also use the corpus for making the term-document matrix but we are using vcorpus because of its explainability after converting it to a term-document matrix.
Making Term-Document Matrix:
tdm <- TermDocumentMatrix(crude,
control = list(removePunctuation = TRUE,
stopwords = TRUE))
tdmOutput:

Here we can see the details of the term-document matrix. Let’s inspect some values from it.
inspect(tdm[100:110, 1:9])
Output:

Here in the output, we can see some of the values of the term-document matrix and some of the information regarding these values. We can also inspect the values using our chosen words from the documents.
inspect(tdm[c("price", "prices", "texas"), c("127", "144", "191", "194")])
Output:

We can also make the document term matrix using the functions provided by the tm library as,
dtm <- DocumentTermMatrix(crude,
control = list(weighting =
function(x)
weightTfIdf(x, normalize =
FALSE),
stopwords = TRUE))
dtmOutput:

Let’s inspect the document term matrix.
inspect(dtm)
Output:
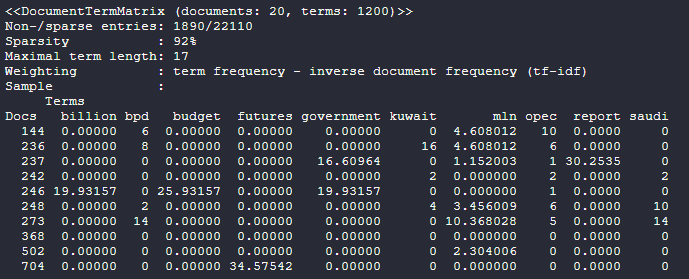
The basic difference between the term-document matrix and document term matrix is that the weighting of the term-document matrix is based on the term frequency (TF) and in the document term matrix the weighting is based on term frequency-inverse document frequency(TF-IDF).
The below image is a representation of a word cloud using the document term matrix that we have made earlier. We can make it using the following codes:
freq <- sort(colSums(as.matrix(dtm)), decreasing=TRUE)
wordcloud(names(freq), freq, min.freq=400, max.words=Inf, random.order=FALSE, colors=brewer.pal(8, "Accent"), scale=c(7,.4), rot.per=0)
Here in the image, we can see that we are required to clean the data to get more proper results. Since the motive of the article is to learn the basic implementation of the document term matrix, we will be focused on this motive only. Let’s see how we can perform it on the Python programming language.
Implementation in Python
In this section of the article, we are going to see how we can make the document term matrix using the python languages and libraries built under python language. In python, there are various ways using which we can perform this. Before going on any of the processes let’s define a document. Here we are taking the sentences from the above-given table. Let’s start by defining the documents.
sentence1 = "I love football"
sentence2 = "Messi is a great football player"
sentence3 = "Messi has won seven Ballon d’Or awards "As we have said that in python, we can do it in various ways. Here we will be discussing two simplest ways for performing this. The first way of making the term-document matrix is to use the functions from the pandas and scikit learn libraries. Let’s see how we can perform this.
Using Pandas
Importing the libraries
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizerAdding the sentences
docs = [sentence1, sentence2, sentence3]
print(docs)Output:

Defining and fitting the count vectorizer on the document.
vec = CountVectorizer()
X = vec.fit_transform(docs)Converting the vector on the DataFrame using pandas
df = pd.DataFrame(X.toarray(), columns=vec.get_feature_names())
df.head()Output:

Here we can see the document term matrix of the documents which we have defined. Now let’s see how we can perform this using our second way where we have a library named textmining which has a function for making the document term matrix from the text data.
Using Text Mining
Installing the library:
pip install textmining3
Output:

Initializing function for making term-document matrix.
import textmining
tdm = textmining.TermDocumentMatrix()
print(tdm)Output:

Here we can see the type of object in the output which we have defined for making the term-document matrix.
Fitting the documents in the function.
tdm.add_doc(sentence1)
tdm.add_doc(sentence2)
tdm.add_doc(sentence3)Converting the term-document matrix in the Pandas data frame.
tdm=tdm.to_df(cutoff=0)
tdmOutput:

Here we can see the document term matrix which we have created using the text mining library.
Application of Term-Document Matrix
We can say that making a term-document matrix from the text data is one of the tasks which comes in between the whole NLP project. Term document matrix can be used in various types of NLP tasks, some of the tasks we can perform using the term-document matrix are as follows:
- By performing the singular value decomposition on the term-document matrix, search results can be improved to an extent. Using it on the search engine, we can improve the results of the searches by disambiguating polysemous words and searching for synonyms of the query.
- Most of the NLP processes are focused on mining one or more behavioural data from the corpus of text. Term document matrices are very helpful in extracting the behavioural data. By performing multivariate analysis on the document term matrix we can reach the different themes of the data.
Final Words
Here in this article, we have seen what is a term-document matrix with an example along with how we can make the term-document matrix using the R and python programming languages. In the end, we have also discussed some major applications of the term-document matrix.
References


























