





|
Listen to this story
|
According to Census 2001, along with 22 official languages, India is home to 122 major languages and 1599 other languages. However, in the present age of digitalisation, most of the content available on the web is in English.
The Narendra Modi-led Central government wants to change that. Earlier this month, the Indian Prime Minister launched Project Bhashini, which aims to provide all Indians with easy access to the internet and digital services in their native languages.
Further, through the project, the government wants to develop a National Public Digital Platform for local languages, which can be leveraged to create products and services for citizens by using technologies such as AI.
Modi launched Bhashini while inaugurating the Digital India Week 2022 event in Gandhinagar.
“Why should intellectual space be restricted to any particular region or language? It is important that the knowledge is shared across India. In NEP, we have stressed languages. We are also working on the National Language Translation Mission and launched Bhashini,” Modi said.
The size and magnitude of the project are staggering, and its benefits are also multifold. With heightened smartphone proliferation, availability of internet in rural areas, and cheaper data rates, India has an unprecedented opportunity to create a blueprint for building the internet for local languages.

Ecosystem
The project will create and nurture an ecosystem where different stakeholders such as institutions, industry players, research groups, academia and individuals will come together to develop an ever-evolving repository of data, training and benchmark datasets, open models, tools and technologies.
“Harness natural language technologies to enable a diverse ecosystem of contributors, partnering entities and citizens for the purpose of transcending language barriers, thereby ensuring digital inclusion and digital empowerment in an ‘Atma Nirbhar Bharat‘,” the project’s vision statement reads.
Public initiatives sometimes suffer from a paucity of data. Bhashini will also break this barrier in the case of Indic languages and level the playing field.

Transcending language barriers
Most of the content available on the web today is predominantly in English, followed by Chinese and other languages. No Indian language makes the top ten list – indicating a staggering lack of content in the local languages.
In fact, 53 percent of the people in India who do not access the web say that they would start accessing it if it had content available in their local languages. In response, the National Language Translation Mission (NLTM) was announced in the 2021-21 budget by Finance Minister Nirmala Sitharaman.
One of the main purposes of Bhashini is to develop a national digital public platform for languages to provide universal access to content, i.e. boost the delivery of digital content in all Indian languages.
This would result in creating a knowledge-based society where information is freely and readily available, making the ecosystem and citizens’ Atmanirbhar’, according to the whitepaper.
“Bhashini Project will utilise our data power and digital infrastructure. It will enable citizens from different regions, speaking different languages, to interact with each other with ease,” Modi said.

Interestingly, the government wants to achieve its goal similarly, like in the case of UPI, CoWin, ONDC, by using public digital assets.
“As part of Bhashini, we are developing the platform to enable all the things to enrich the Indic language AI models for various tasks like Translation, Speech to Text, Text to Speech, Image to Text etc. Once these models are developed, they would be used in various applications like document translations for every domain like Judicial, Medical, Education etc. Parliamentary speeches can be broadcasted in all languages simultaneously.
“All government reports/materials/communications can be generated in all the official languages. The core idea is to stop language being a barrier for any industry,” Aravinth Bheemaraj, who is currently leading the Universal Language Contribution API (ULCA) team, said.
Universal Language Contribution API
ULCA is the largest repository of datasets of Indian languages developed by the Ministry of Electronics and Information Technology (MeiTY). It is a standard API and open scalable data platform for datasets, models and benchmarking for the Indian languages. Bhashini will capture all data and model contributions through ULCA.
“ULCA will help researchers develop language AI technologies including machine translation or NMT, Automatic Speech Recognition (ASR), Text-To-Speech (TTS) and Optical Character Recognition (OCR) in the 22 Indian languages,” Bheemaraj said.
All the APIs used in ULCA are documented as open APIs via the Swagger platform. It already has large datasets of Indic languages collected over time.
The datasets contain records from multiple domains such as news, education, finance, healthcare and sports. According to Bheemaraj, these records are collected through various methods, such as machine translation with post-editing, auto-aligned algorithms, and crowdsourcing.
Further, it contains a repository of language AI models in Indian languages trained with the existing datasets. These models can perform automatic translation of text from one Indian language to another, transcription of audio data in Indian languages, and detection of text in Indian languages from images, text to speech, wherein text is converted into natural-sounding speech.
So far, more than 90 models in machine translation, ASR, OCR and TTS have been submitted.
Bhasha Daan
Bhasha Daan, as the name suggests, is an initiative to crowdsource language inputs for multiple Indic languages. The initiative is a part of Project Bhashini. The aim here is to create large datasets for Indic languages, which can be used to train AI models to be used by different stakeholders to create products or services for the betterment of society.
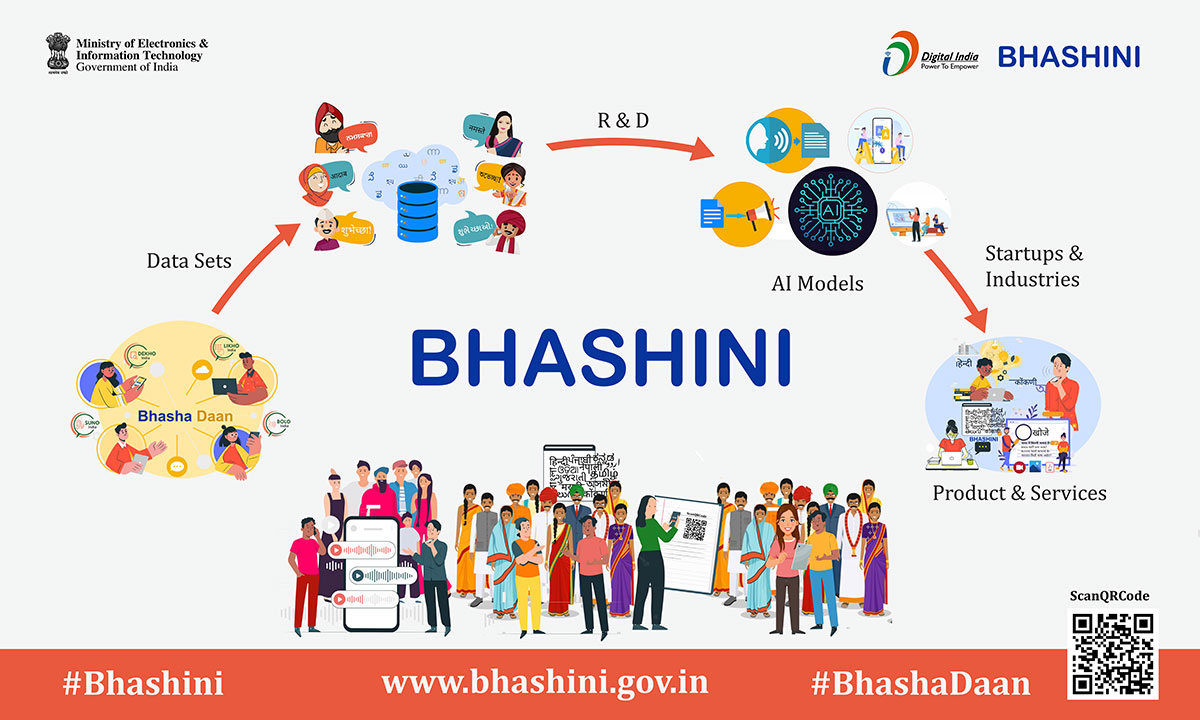
Another interesting aspect of this initiative is that the entire codebase for Bhasha Daan is open-sourced so that different stakeholders, be it NGOs or startups, can run campaigns for data collection. This will allow decentralised and customised data collection and contribute back to the data repository in bulk via ULCA.
One can contribute to the project anonymously as the portal doesn’t require you to log in for validation. The bigger aim is to create an open-source repository that anyone can access.

Stakeholders
Bhashini Maintainer : MeiTY (IT Ministry), DIC (Digital India Corporation)
Platform provider : Azure (Microsoft has provided some credits). Eventually this would be ported to CDAC infrastructure.
Funding : Bootstrap and initial funds were from EkStep Foundation. Eventually goes to MeiTY
Code Developers : Tarento Technologies, Thoughworks, AI4Bharat
Model Contributors : AI4Bharat, IIT Bombay, IIT Madras, IIIT Hyderabad, CDAC
Dataset Contributors : AI4Bharat, IIT Madras, IIT Bombay, IIIT Hyderabad, CDAC, etc.





















