





The 2024 edition of CVPR 2024, the prestigious annual conference for computer vision and pattern recognition, took place from June 17 to 21 in Seattle, Washington.
Google Research was one of the key sponsors, which presented over 95 papers on various topics including computer vision, AI, machine learning, deep learning, and related areas from academic, applied, and business R&D perspectives. It also had an active involvement in over 70 workshops and tutorials.
“Computer vision is rapidly advancing, thanks to work in both industry and academia,” said David Crandall, professor of computer science at Indiana University, Bloomington and CVPR 2024 program co-chair.
The event saw 11,532 entries, out of which only 2,719, that is 23.58%, were accepted. Let’s take a look at the top papers presented by Google this time.
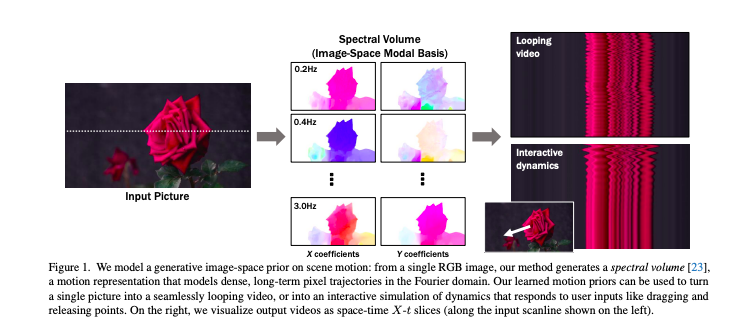
Generative Image Dynamics
Generative Image Dynamics presents a novel approach for generating realistic image sequences from a single input image by the authors. This work presents a generative model that predicts the temporal evolution of images, capturing spatial and temporal dependencies.
This approach has potential applications in video prediction and by generating realistic image sequences from a single input, it advances generative modelling and opens new possibilities for creative and interactive applications.
Rich Human Feedback for Text-to-Image Generation
The paper proposes a novel approach to leveraging human feedback for improving text-to-image generation models.
The framework allows users to give detailed feedback on generated images, such as annotations, sketches, and descriptions. This feedback is used in a novel training strategy to fine-tune and improve the text-to-image generation model.
Incorporating rich human input also addresses the limitations of current models and advances user-centric generative systems.
DiffusionLight: Light Probes for Free by Painting a Chrome Ball
The paper introduces a diffusion model that can efficiently estimate the 3D lighting environment from a single 2D image.
The diffusion model enables real-time applications like virtual try-on and augmented reality, with effective lighting estimation demonstrated on diverse inverse rendering benchmarks, surpassing prior state-of-the-art methods.
The authors have also released the source code and a demo of the Diffusion Light system, enhancing accessibility for further research and development.

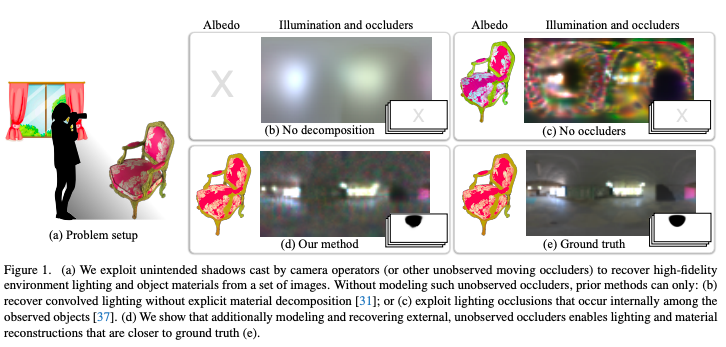
Eclipse: Disambiguating Illumination and Materials using Unintended Shadows
This paper, published in May 2024 by a team of Google researchers, presents Palm-E, a large language model designed for dialogue applications. The model is based on the Pathways Language Model (PaLM) architecture, which is a scaled-up version of the Transformer model.
The authors fine-tuned the model on a large dataset of conversational data, including both human-human and human-bot conversations. The authors evaluated Palm-E on a range of dialogue tasks, including open-domain conversation, task-oriented dialogue, and dialogue safety.
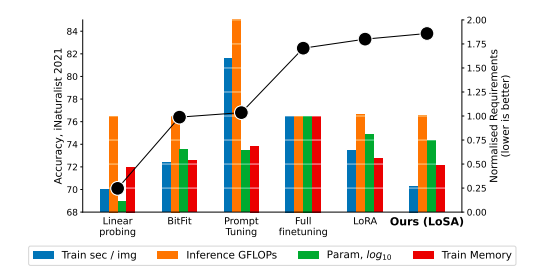
Time-, Memory- and Parameter-Efficient Visual Adaptation
This paper was published by a team of researchers from the University of Tubingen.
The paper explores the use of deep reinforcement learning to study the evolution of cooperation in social dilemmas. Social dilemmas are situations where individual self-interest conflicts with the collective good, and cooperation is often required to achieve the best outcome for the group.
They found that the agents were able to learn cooperative strategies in some cases, but that the emergence of cooperation depended on several factors, including the payoff structure of the game and the presence of noise.
Video Interpolation with Diffusion Models
Here, the authors argue that traditional supervised learning approaches for summarisation are limited by the quality and diversity of the available training data, and that RL with human feedback can help address these limitations.
They also propose a framework which involves training a reward model to predict the quality of summaries based on human feedback, and then using this reward model to train a summarisation model using RL.
It also includes an analysis of the reward model and the summarisation model, and discusses several challenges and limitations of using RL with human feedback for summarisation.

WonderJourney: Going from Anywhere to Everywhere
Another paper here, presents a new approach for generating images from text using diffusion models. Diffusion models are a class of generative models that have recently shown promising results in image synthesis tasks. The authors first train a text encoder to map text descriptions to a latent space. They then use this latent space to condition a diffusion model to generate images.
The diffusion model is trained using a denoising objective, where the model learns to progressively remove noise from a noisy image until it matches the target image.
The authors evaluated their approach on several benchmark datasets for text-to-image synthesis and compared it to several state-of-the-art models.



































