





The AI market is currently crowded with various models, as major players such as OpenAI, Meta, and Google continuously refine their offerings. However, the question remains: which models will developers choose, and is it feasible for AI startups and big tech companies to offer these models for free?
“If you’re only selling models, for the next little while, it’s gonna be a really tricky game,” said Cohere founder Aidan Gomez in a recent interview. By selling models, he meant selling API access to those AI models. OpenAI, Anthropic, Google, and Cohere offer this service to developers, and they all face a similar problem.
“It’s gonna be like a zero margin business because there’s so much price dumping. People are giving away the model for free. It’ll still be a big business, it’ll still be a pretty high number because people need this tech — it’s growing very quickly — but the margins, at least now, are gonna be very tight,” he explained.
Interestingly, OpenAI just made $510 million from API services while it made $1.9 billion from ChatGPT subscription models.
Gomez hinted that Cohere might offer more than just LLMs in the future. “I think the discourse in the market is probably right to point out that value is occurring both beneath, at the chip layer—because everyone is spending insane amounts of money on chips to build these models in the first place—and above, at the application layer.”
Recently, Adept was acqui-hired by Amazon, Inflection by Microsoft, and Character.ai by Google. “There will be a culling of the space, and it’s already happening. It’s dangerous to make yourself a subsidiary of your cloud provider. It’s not good business,”said Gomez.
Sully Omar, Co-founder and CEO of Cognosys, echoed similar sentiments and said, “It won’t be long until we see options like ‘login’ with OpenAI/Anthropic/Gemini. In the next 6-8 months, we’re likely to see products that use AI at a scale 100 times greater than today.”
He added that from a business standpoint, it doesn’t make sense to upsell customers on AI fees. “I’d rather charge based on the value provided,” he said.
Omar noted that the current system, which relies on API keys, is cumbersome for most users. “90% of users don’t understand how they work. It’s much easier for users to sign into ChatGPT, pay for compute to OpenAI/Gemini, and then use my app or service at a lower price,” he explained.
He also criticised the credits-based pricing model, suggesting that it is ineffective as it requires constantly managing margins on top of LLM fees.
The rise of LLMs has ignited another debate: will generative AI lead to more APIs or the end of APIs?
“The AI model market is mirroring the early days of cloud computing, where infrastructure (IaaS) was a low-margin game. As cloud providers realised, value creation shifted towards higher-margin services like SaaS and PaaS, layering specialised applications on top of core infrastructure,” said Pradeep Sanyal, AI and ML Leader at Capgemini.
“AI startups must move beyond selling raw models to offering differentiated, application-focused solutions,” he explained.
Google and OpenAI Compete for Developer Attention
OpenAI recently announced the launch of fine-tuning for GPT-4o, addressing a highly requested feature from developers. As part of the rollout, the company is offering 1 million training tokens per day for free to all organisations through September 23.
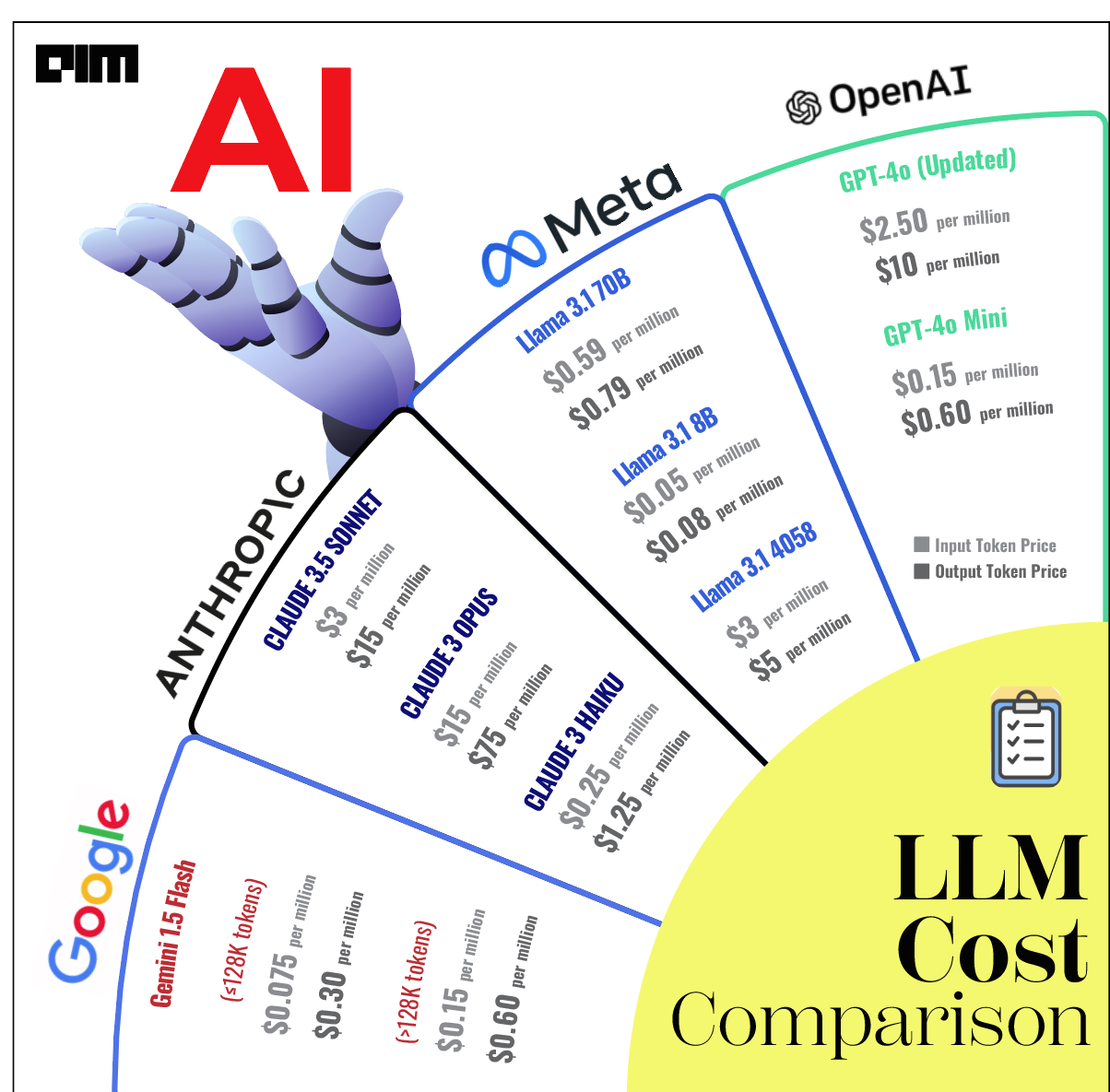
The cost for fine-tuning GPT-4o is set at $25 per million tokens. For inference, the charges are $3.75 per million input tokens and $15 per million output tokens. Additionally, GPT-4o mini fine-tuning is available to developers across all paid usage tiers.
This development comes after Google recently reduced the input price by 78% to $0.075/1 million tokens and the output price by 71% to $0.3/1 million tokens for prompts under 128K tokens (cascading the reductions across the >128K tokens tier as well as caching) for Gemini 1.5 Flash.
Moreover, Google is giving developers 1.5 billion tokens for free everyday in the Gemini API. The Gemini 1.5 Flash free tier includes 15 requests per minute (RPM), 1 million tokens per minute (TPM), and 1,500 requests per day (RPD). Users also benefit from free context caching, allowing up to 1 million tokens of storage per hour, as well as complimentary fine-tuning services.
Logan Kilpatrick, Lead at Google AI Studio, said that they are likely to offer free tokens for the next several months.
Meanwhile, OpenAI recently launched GPT-4o mini, priced at $0.15 per million input tokens and $0.60 per million output tokens. This model is significantly more affordable than previous frontier models and over 60% cheaper than GPT-3.5 Turbo. The GPT-4o mini retains many of GPT-4o’s capabilities, including vision support, making it suitable for a broad range of applications.
Additionally, OpenAI has reduced the price of GPT-4o. With the new GPT-4o-2024-08-06, developers can save 50% on input tokens ($2.50 per million) and 33% on output tokens ($10.00 per million) compared to the GPT-4o-2024-05-13 model.
https://x.com/ofermend/status/1822783034296512597
Meta’s Llama 3.1 is a Game Changer
According to Harneet Singh, founder of Rabbitt AI, Meta’s latest model, Llama 3.1 70B, is the most cost-effective option, priced at $0.89 per million tokens while offering capabilities similar to OpenAI’s GPT-4o. “This cost-benefit ratio makes it an attractive choice for budget-conscious enterprises,” he said.
The company used Groq’s hosted APIs for Llama 3.1.
Llama 3.1 70B model has an input token price of $0.59 per million tokens and an output token price of $0.79 per million tokens, with a context window of 8,000 tokens on Groq.
In contrast, the 8B model features a more affordable pricing structure, with input tokens costing $0.05 per million and output tokens priced at $0.08 per million, also with a context window of 8,000 tokens.
In comparison, the inference of Llama 3.1 405B costs $3 per 1M tokens and $5.00 per million output tokens on Fireworks.
“I don’t think it’s possible to make it cheaper without some loss in quality. GPT-4o mini offering a comparable quality costs $0.15 per 1M input tokens and $0.6 per 1M output tokens (and half this price when called in batches),”said Andriy Burkov, machine learning lead at TalentNeuron.
“The math here is broken. Either OpenAI managed to distill a ~500B parameter model into a ~15B parameter model without a quality loss or they use crazy dumping. Any ideas?,” he pondered.
Conclusion
While open-source models like Llama 3.1 70B offer remarkable cost efficiency, proprietary models such as GPT-4o deliver unparalleled quality and speed, albeit at a higher price point.
GPT-4o provides the most comprehensive multimodal capabilities, supporting text, image, audio, and video inputs. It is suitable for applications requiring diverse input types and real-time processing.
Gemini 1.5 Flash integration with Google’s ecosystem can be a significant advantage for businesses already using Google’s services, offering seamless integration and additional functionalities.
The choice of model thus largely depends on the specific needs and budget constraints of the enterprise.

























