





|
Listen to this story
|
IBM has announced the release of a family of Granite code models to the open-source community, aiming to simplify coding for developers across various industries. The Granite code models are built to resolve the challenges developers face in writing, testing, debugging, and shipping reliable software.
Register for Rakuten Product Conference 2024 >
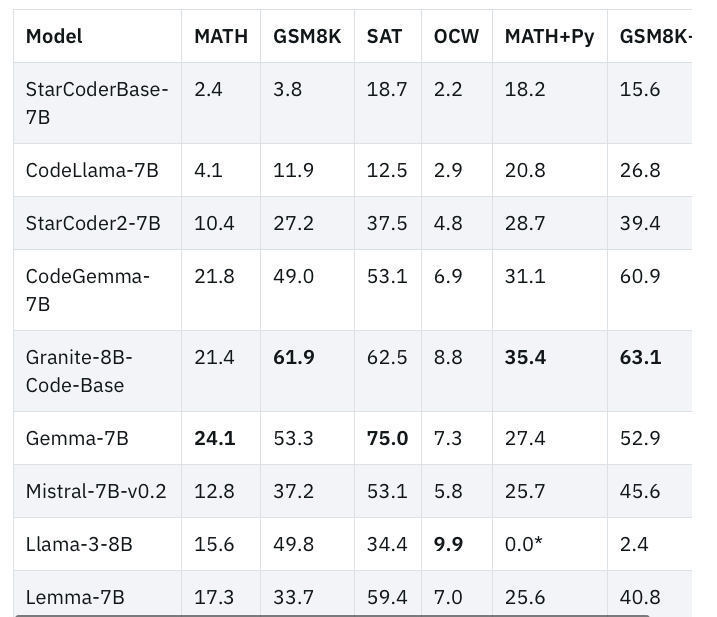
IBM has released four variations of the Granite code model, ranging in size from 3 to 34 billion parameters. The models have been tested on a range of benchmarks and have outperformed other comparable models like Code Llama and Llama 3 in many tasks.
The models have been trained on a massive dataset of 500 million lines of code in over 50 programming languages. This training data has enabled the models to learn patterns and relationships in code, allowing them to generate code, fix bugs, and explain complex code concepts.
The Granite code models are designed to be used in a variety of applications, including code generation, debugging, and testing. They can also be used to automate routine tasks, such as generating unit tests and writing documentation. They cater to a wide range of coding tasks, including complex application modernisation and memory-constrained use cases.
“We believe in the power of open innovation, and we want to reach as many developers as possible,” said Ruchir Puri, chief scientist at IBM Research. “We’re excited to see what will be built with these models, whether that’s new code generation tools, state-of-the-art editing software, or anything in between.”
The models’ performance has been tested against various benchmarks, showcasing their prowess in code synthesis, fixing, explanation, editing, and translation across major programming languages like Python, JavaScript, Java, Go, C++, and Rust.
The Granite code models are available on Hugging Face, GitHub, watsonx.ai, and RHEL AI, and are released under the Apache 2.0 license.
























