





Feature engineering plays a crucial role in many of the data modelling tasks. This is simply a process that defines important features of the data using which a model can enhance its performance. In time series modelling, feature engineering works in a different way because it is sequential data and it gets formed using the changes in any values according to the time. In this article, we are going to discuss feature engineering in time series and also we will cover an implementation of feature engineering in time series using a package called tsfresh. The major points to be discussed in the article are listed below.
Table of contents
- Feature engineering in time series
- What is tsfresh?
- Implementing tsfresh for feature engineering
Let’s start with understanding what features engineering in time series.
Feature engineering in time series
In supervised learning, feature engineering aims to scale strong relationships between the new input and output features. Talking about the time series modelling or sequential modelling we don’t feed any input variable to the model or we don’t expect any output variable (input and outputs are in the same variable ). Since the features of data and methods that we know about the time series modelling work in a different nature. This data consists of time features in the data with some values that are changing with the time feature.
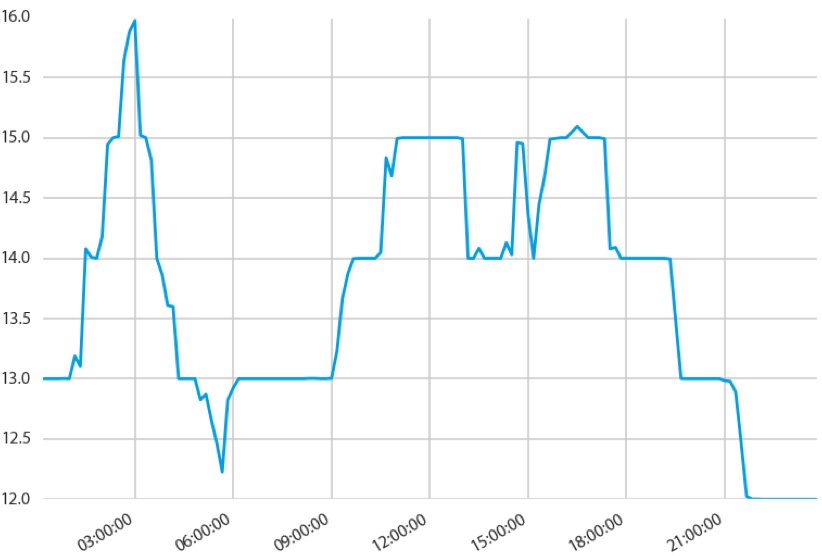
By looking at such data we can say that features of any time series data are the time or the main feature we use in modelling is time and that is also responsible for predicting good results. In time series we are required to perform feature engineering with the time variable. For example, we may require engineering dates from the year where we are finding the value of our sales is increasing. Time series data gets created using the independent variable where time is the most common variable. The below image can be an example of a time series plot.
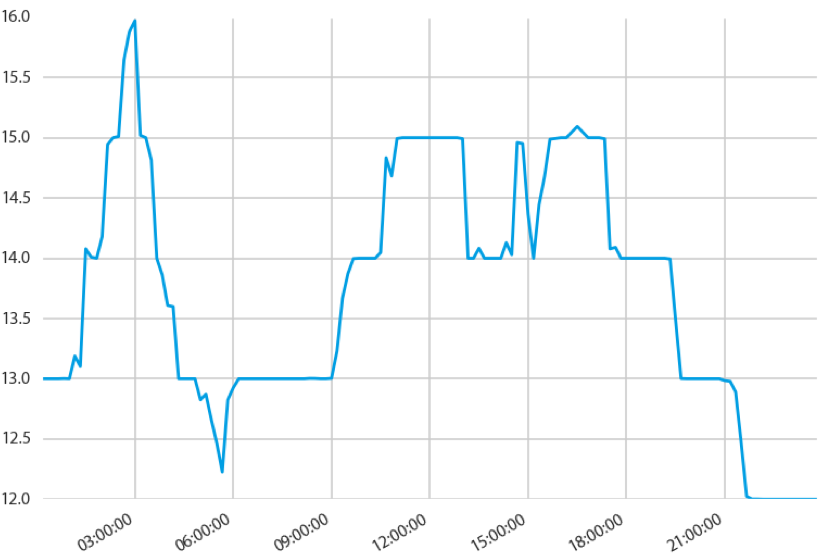
Image source
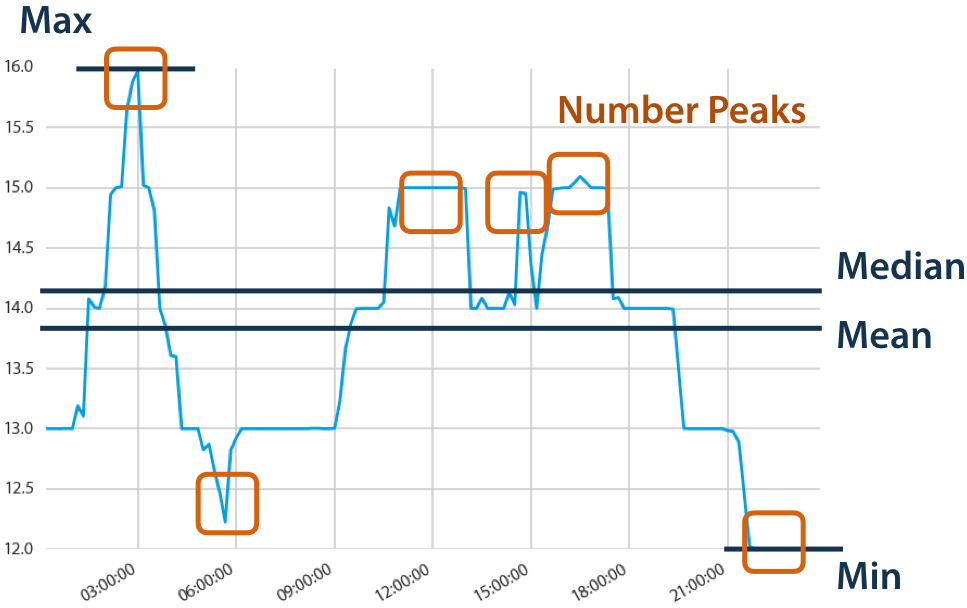
In the plot, we can see that we have changed the values as time moves on. We may want to find some of the characteristics from this data. Examples of characteristics can be the maximum or minimum value, average value, or temporary peak in the data. Take an example from the below image.

Here we can see what the feature can consist of by time-series data. We can perform time-series feature engineering using the tsfresh package. Let’s understand what is tsfresh.
What is tsfresh?
tsfresh is an open-source python package that can help us in feature engineering of time series data. As we have discussed before, the time series is sequential data so this package can also be used with any kind of sequential data. One thing that is mandatory about the data it should have generated using an independent variable. For example, in time-series data, we find the time variable is an independent variable.
Utilizing this tool we can extract features and we can perform analysis based on the new insights. Feature extraction is also helpful in making clusters from the time series or we can also perform classification and regression tasks using feature extraction.
One more thing that can be very useful for us in this package is that it is compatible with pandas library for data manipulation and also it is compatible with the sklearn library that helps us in providing various machine learning models. Let’s discuss how this package can be used.
Implementation
We can install this package using the following lines of codes:
!pip install tsfresh
After the installation, we are ready to use the package. To understand the nature of working of tsfresh we are going to perform a classification task using tsfresh provided dataset that consists of information about robot failure. In the data, we find that each robot has collected time series from different sensors. Let’s load the data.
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, \
load_robot_execution_failures
download_robot_execution_failures()Defining x and y
x, y = load_robot_execution_failures()
Here we have features of the data in x instance and the target feature is in the y instance.
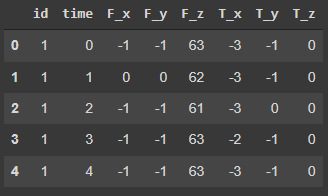
x.head()
Output:
y.head()
Output:
In the head of x we can see that we have 6 columns in the data name as F_x, F_y, F_z, T_x, T_y, T_z are the time series and the id column gives the different robots. Let’s visualize some of the data using the matplotlib.
import matplotlib.pyplot as plt
x[x['id'] == 4].plot(subplots=True, sharex=True, figsize=(12,12))
plt.show()Output:
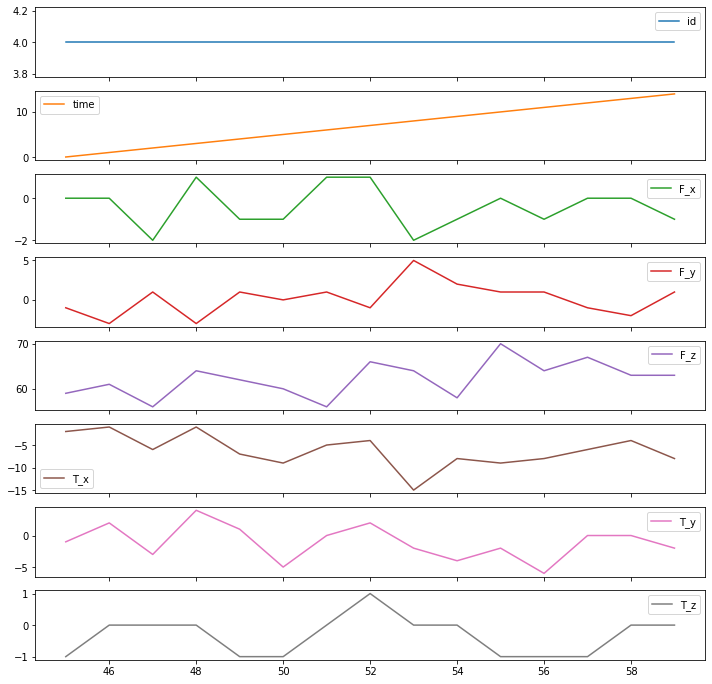
In the above output, we can see the time series for sample id 4 that is not representing any failure. Let’s check for another sample.
x[x['id'] == 14].plot(subplots=True, sharex=True, figsize=(12,12))
plt.show()Output:
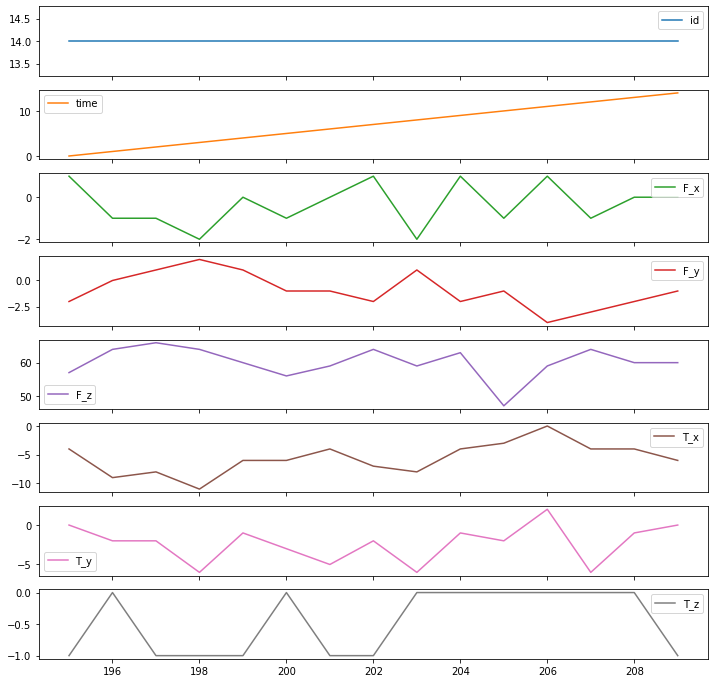
Here we can see that we have got some failures. Let’s check whether our model can capture these details or not.
Extracting features
from tsfresh import extract_features
features = extract_features(x, column_id="id", column_sort="time")Output:

Here the process of feature extraction from time series is completed. Let’s see how many features we have from these different time series.
features
Output:
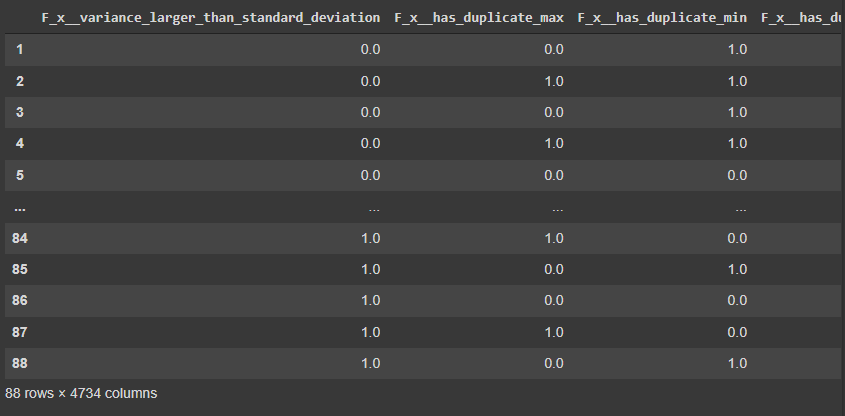
Here we can see 88 rows and 4734 columns in extracted features. There can be many non-values in extracted features that can be removed using the following lines of codes.
from tsfresh.utilities.dataframe_functions import impute
impute(features)Now we can select relevant features using the following lines of codes.
from tsfresh import select_features
filtered_features = select_features(features, y)
filtered_features
Output:
In the above output, we can see that there are only 682 columns presented after the filtration of the features. Here we have performed two things with the data: first, we extracted the features from the data and second, we have filtered the extracted features.
Now we can compare the results of any model from sklearn using the data with all features and the data with filtered features. Let’s split the data into tests and train.
from sklearn.model_selection import train_test_split
X_feature_train, X_feature_test, y_train, y_test = train_test_split(features, y, test_size=.4)
X_filtered_train, X_filtered_test = X_feature_train[filtered_features.columns], X_feature_test[filtered_features.columns]Let’s fit the data with all the features in a decision tree model.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
classifier_feature = DecisionTreeClassifier()
classifier_feature.fit(X_feature_train, y_train)
print(classification_report(y_test, classifier_feature.predict(X_feature_test)))Output:
Here we have got some good results with all the features. Let’s check a model using data that has been filtered.
classifier_filtered = DecisionTreeClassifier()
classifier_filtered.fit(X_filtered_train, y_train)
print(classification_report(y_test, classifier_filtered.predict(X_filtered_test)))Output:
Here we can see that a similar model has improved its performance with the filtered model.
Final words
Here in this article, we have discussed feature engineering in time series. Along with that, we have discussed a python package named tsfresh, that can be used in feature engineering of time series. Using some of the modules we have performed feature engineering and after feature engineering, we find some improvements in the model performance.
References



























{kind=link}
{kind=link}