





|
Listen to this story
|
A feature store keeps track of frequently used features. Feature Stores have evolved into a critical component of data infrastructure for machine learning systems. They handle the whole lifetime of features, from training multiple models to giving low-latency access to features for model inference by online applications. This article introduces Feast, a data management system for managing and providing machine learning features. With features provided by Feast, we will cover here how to build our own feature store. Following are the topics to be covered.
Table of contents
- What is a Feature store?
- What kind of Feature stores are available?
- Why use the Feature store?
- Are there any drawbacks to the feature store?
- Creating a Feature store using Feast
Let’s start with a high-level idea of a feature store.
What is a Feature store?
Simply put, a feature store is a tool used for storing commonly used features. Typically, when data scientists develop features for a machine learning model, those features can be added to the feature store so that it can be reused later.
The process of developing features is also known as feature engineering, and it is a complex but necessary component of any machine learning process. Better features equal better models, which equals a better business outcome.
The Feature Store for machine learning is a feature computation and storage service that allows features to be registered, found, and utilized in both ML pipelines and online applications for model inference. Feature Stores are frequently required to store huge amounts of feature data while also providing low-latency access to features for online applications.
Producing a pipeline for generating a new feature is only one component of the labour involved in creating a new feature. To get to that point, undoubtedly you need to go through a long process of trial and error with a wide range of features until it is satisfactory. Then it is needed to be computed and saved as part of an operational pipeline, which varies based on whether the feature is online or offline.
A feature store, on the other hand, is more than just a data layer; it is also a data transformation service that allows customers to change raw data and store it as features that can be utilized by any machine learning model.

Are you looking for a complete repository of Python libraries used in data science, check out here.
Are there any types of Feature stores?
A feature store is often built as a dual-database system, with a low latency online feature store (typically a key-value store or real-time database) and a scale-out SQL database for storing huge amounts of feature data for training and batch applications. There are two ways a feature store can be utilized.
- Offline – Some characteristics are computed offline as part of a batch task. For instance, average monthly spending. They are mostly employed by offline processes. Because of their nature, these traits might take some time to develop. Offline features are often generated using frameworks like Spark or by conducting SQL queries against a given database and then utilizing a batch inference procedure.
- Online – These characteristics are a little more challenging since they must be computed quickly and are frequently served in milliseconds. Calculating a z-score, for example, for real-time fraud detection. In this scenario, the pipeline is created in real-time by computing the mean and standard deviation across a sliding window. These computations are substantially more difficult, needing both quick computation and fast data access. The information can be kept in memory or a rapid key-value database.
Why use the Feature store?
Reduced development time
Data engineering setups are frequently seen as a spun-out process. Some attributes are difficult to compute and necessitate constructing aggregation, whilst others are rather simple. As a result, the idea behind a feature store is to abstract all of those engineering layers and make it simple to read and write features.
Working with a feature store abstracts this layer so that when a developer is looking for a feature, he or she may use a simple API to retrieve the data instead of writing technical code.
Model deployment in production is smooth
One of the most difficult aspects of deploying machine learning in production is that the features used for training a model in the development environment are not the same as the characteristics in the production serving layer. As a result, establishing a consistent feature set across the training and serving layers allows for a more seamless deployment process, guaranteeing that the trained model accurately reflects how things will operate in production.
Better model performance
The feature store stores extra metadata for each feature in addition to the actual features. For example, a statistic that demonstrates the influence of a feature on the model with which it is related. This information may greatly assist data scientists in picking characteristics for a new model, allowing them to focus on those that have had the most influence on similar current models.
Track lineage and address regulatory compliance
It is critical to trace the lineage of algorithms being built to follow rules and laws, especially when the AI models being generated serve areas such as Healthcare, Financial Services, and Security. To do this, insight into the complete end-to-end data flow is required to better understand how the model generates its outputs. Because features are created as part of the process, it is necessary to follow the flow of the feature creation process. The lineage of the feature could be retained in a feature store. This offers the essential tracking information, capturing how the feature was developed, as well as the insight and reports required for regulatory compliance.
Are there any drawbacks to the feature store?
There are certain drawbacks of the feature store which are listed below.
- There is a Potential inflexibility in the feature store. Organizations require a unique feature store for each entity type.
- Complex integration may necessitate the integration of many technologies such as data warehouses, streaming pipelines, and processing engines.
- Limits model customization-Various applications may benefit from different feature encodings that would be unnoticed if they all used the same feature store.
Creating a Feature store using Feast
Let’s start with installing the Feast package. If using the google Colab notebook then first install the below-mentioned dependency.
! pip install tf-estimator-nightly==2.8.0.dev2021122109
%%sh pip install feast -U -q pip install Pygments -q
The ‘%%sh’ is a shell command-line interpreter that will interpret the command line as it was in the Linux operating system.
Create the feature repository
! feast init feature_repo

This command will initialize the feature repository which is a directory that holds the feature store’s settings as well as individual features. This configuration is written in Python/YAML.
In this article, we will be using a demo repository by Feast. Let’s inspect the contents of the repository.
%cd feature_repo !ls -R
‘%cd’ will change the directory to the repository created.
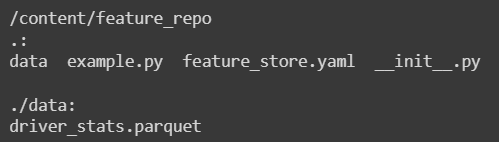
Let’s have a look at the project configuration.
! pygmentize feature_store.yaml
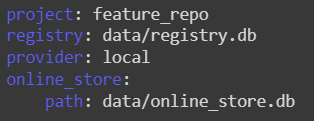
Now the feature repository is created and the project is configured. The data is to be loaded and the feature is to be defined.
import pandas as pd from datetime import datetime, timedelta import sqlite3 from feast import FeatureStore
raw_df=pd.read_parquet("data/driver_stats.parquet")
raw_df.head()

In this demo repository, there is already a predefined file containing features so need to define features. Let’s have a look at those features.
! pygmentize -f terminal16m example.py
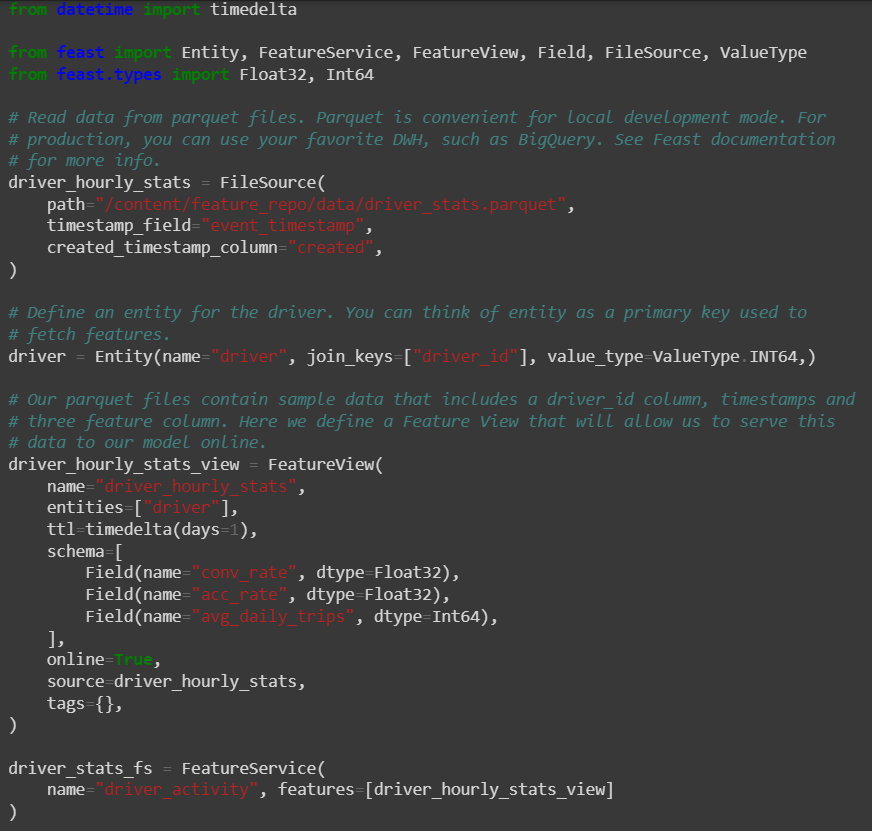
Now the features are defined and they need to be applied to the data.
! feast apply
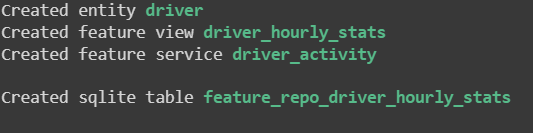
The features have been applied and the data is ready to be split into training and testing sets.
dict_df = pd.DataFrame.from_dict(
{
"driver_id": [1001, 1002, 1003],
"label_driver_reported_satisfaction": [1, 5, 3],
"event_timestamp": [
datetime.now() - timedelta(minutes=11),
datetime.now() - timedelta(minutes=36),
datetime.now() - timedelta(minutes=73),
],
}
)
store = FeatureStore(repo_path=".")
training_data = store.get_historical_features(
entity_df=dict_df,
features=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate",
"driver_hourly_stats:avg_daily_trips",
],
).to_df()

Let’s upload these features to the online store so that they could be utilized globally in the hub.
! feast materialize-incremental {datetime.now().isoformat()}

Once the features are uploaded to the database there must be some directory to be formed. Let’s check those directories and try to extract the newly uploaded features from the database using SQL.
print("--- Data directory ---")
!ls data

There are three directories one with the raw data, the other with the updated features and the implementation of those features on the data (updated data).
con_online = sqlite3.connect("data/online_store.db")
print("\n--- Schema of online store ---")
print(
pd.read_sql_query(
"SELECT * FROM feature_repo_driver_hourly_stats", con_online).columns.tolist())
con_online.close()

The ‘sqlite3’ will make a connection with the database and the data could be extracted by simply writing the SQL query.
Conclusion
Feature stores are the tool that organizations may utilize to generate several models based on one or a few entities. A feature store’s main advantage is that it contains the logic of feature transformations, allowing it to automatically transform fresh data and provide examples for training or inference. With this hands-on article, we have understood feature stores and their importance to a data science project.


































