





As we know, currently big data is in a constant phase of growth as well as evolution. By IDC estimation, global revenue from big data will reach $203 billion by the year 2020 and also it is predicted that there will be around 440,000 big data-related job roles in the US alone even with only 300,000 skilled professionals to grab them.
Now, professionals, students, freshers and entrepreneurs need to be updated with the emerging Big Data technologies for better growth in this decade. Hence, in this article, I am listing 7 emerging Big Data technologies and trends that will help us to be more successful with time.
Apache Beam
Apache is a project model which got its name from combining the terms for big data processes batch and streaming. It’s a single model which we can use for both cases.
Simply put, Beam = Batch + strEAM.
We only required to design a data pipeline once, and further choose from multiple processing frameworks, under the Beam model. We can choose to make our own batch or stream because our data pipeline is portable as well as flexible. We have one more flexibility that every time we want to choose a different processing engine or when we need to process batch or streaming data, we don’t need to redesign it.
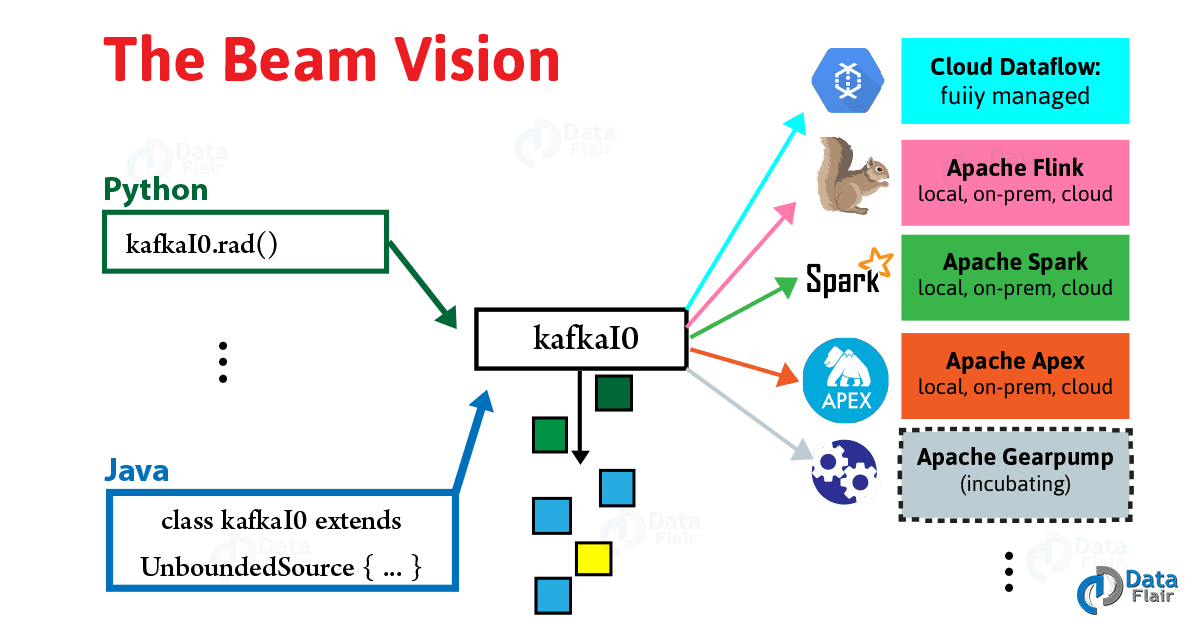
Hence, from much greater agility and flexibility, teams can benefit to reuse data pipelines, and also can select the right processing engine for the multiple use cases.
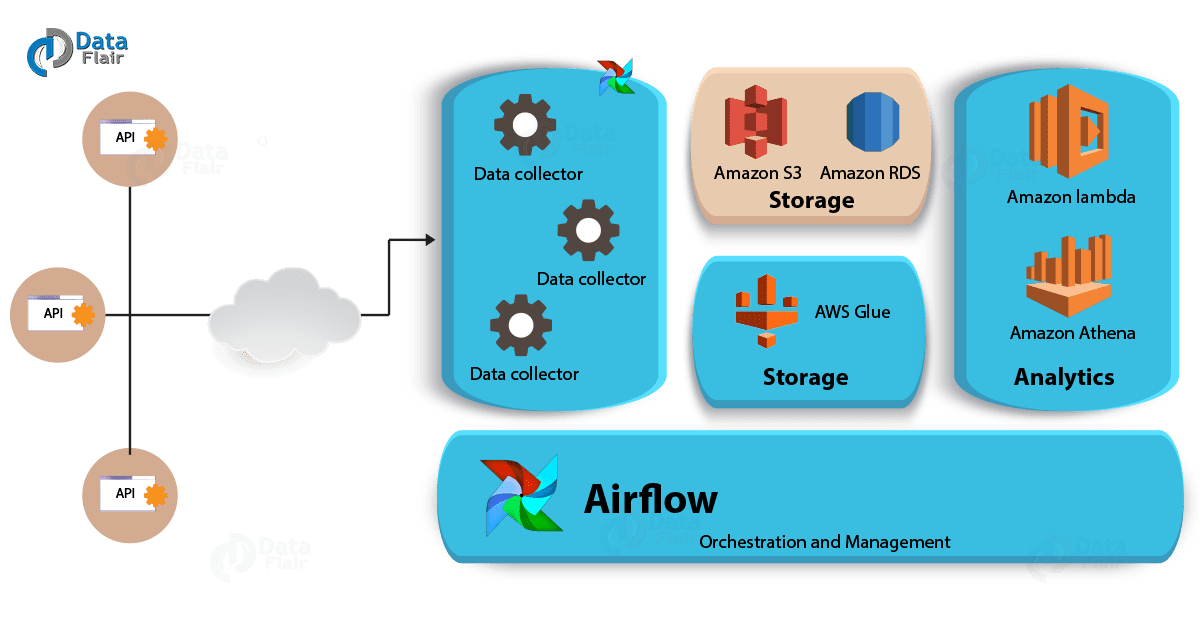
Apache Airflow
While it comes to Airflow, it turned into the ideal technology for automated, smart scheduling of Beam pipelines in order to optimize processes and organize projects.
Moreover, pipelines are configured via code rendering them dynamic, and metrics have visualized graphics for DAG and Task instances, along with other beneficial capabilities and features. In addition, Airflow has the ability to rerun a DAG instance, if and when there is a failure.
Apache Cassandra
Cassandra enables failed node replacements without having to shut anything down and automatic data replication across multiple nodes. Moreover, it is a scalable and nimble multi-master database.
As its best features, it is a NoSQL database with the scalability and high availability. Since it is designed with no master-slave structure, all nodes are peers and fault-tolerant.
Therefore, we can say it differs from the traditional RDBMS, and some other NoSQL databases.
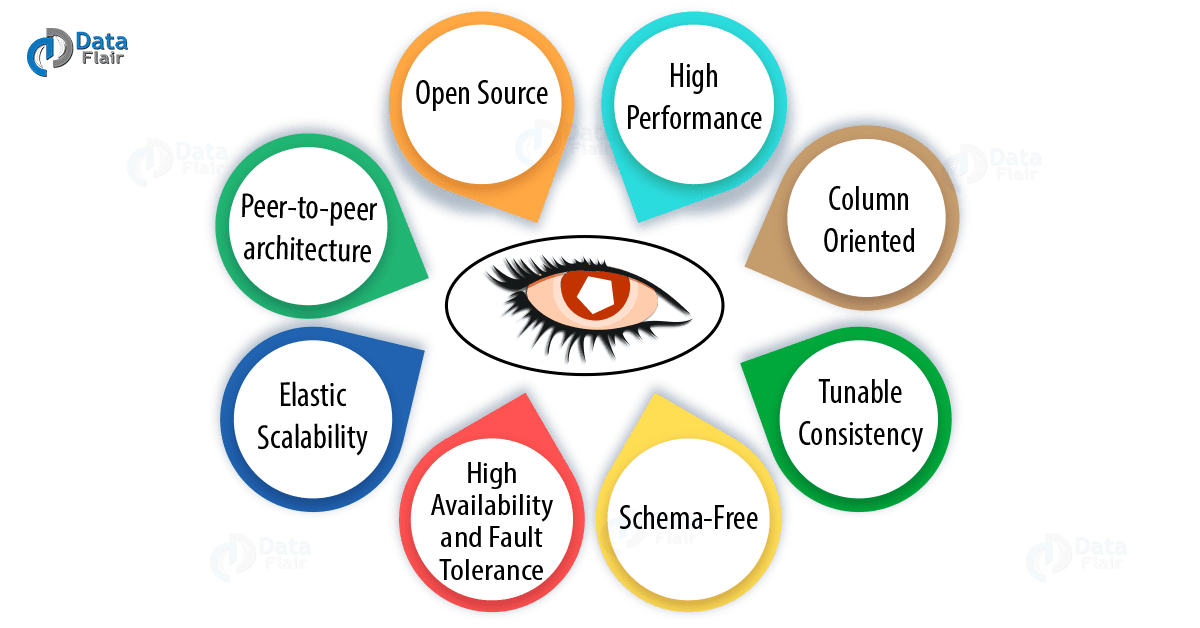
Also, even without any application downtime, it makes it extremely easy to scale out for more computing power.
Apache Carbon Data
For incredibly fast analytics on big data platforms such as Hadoop and Spark, Apache Carbon Data is an indexed columnar data format. As its job role, it solves the problem of querying analysis for different use cases. It can be multiple types of querying needs from OLAP vs detailed query, big scan, and small scan and many more.
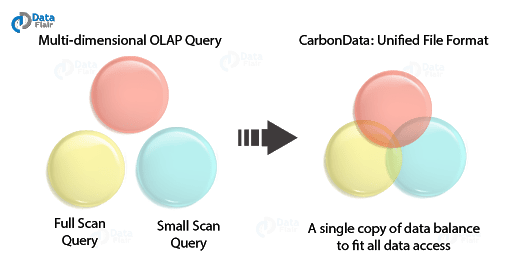
Moreover, we can access through a single copy of data and use only the computing power needed with Apache Carbon since the data format is so unified, hence it makes our queries run much faster.
Apache Spark
Undoubtedly, we can say, Apache Spark is the most widely utilized Apache projects and a popular choice for incredibly fast big data processing (cluster computing). It attains built-in capabilities for real-time data streaming, SQL, machine learning, graph processing and many more.

One of the major reason for its popularity is that it is optimized to run in-memory and also can enable interactive streaming analytics where unlike batch processing, it is possible to analyze vast amounts of historical data with live data to make real-time decisions. For example, predictive analytics, fraud detection, sentiment analysis and many more.
TensorFlow
Especially, for machine intelligence, it is an extremely popular open-source library that enables far more advanced analytics at scale. TensorFlow is flexible enough to support experimentation with new machine learning models and system-level optimizations along with large-scale distributed training and inference.
There is one major reason for which TensorFlow is so popular among people that is there was no single library that deftly catches the breadth and depth of machine learning and possesses such huge potentials, before TensorFlow.
Additionally, TensorFlow is well documented, very readable, and expected to continue to grow into a more vibrant community.
Docker and Kubernetes
Both Docker and Kubernetes are container and automated container management technologies. And, both do speed deployments of applications. Image below shows how.
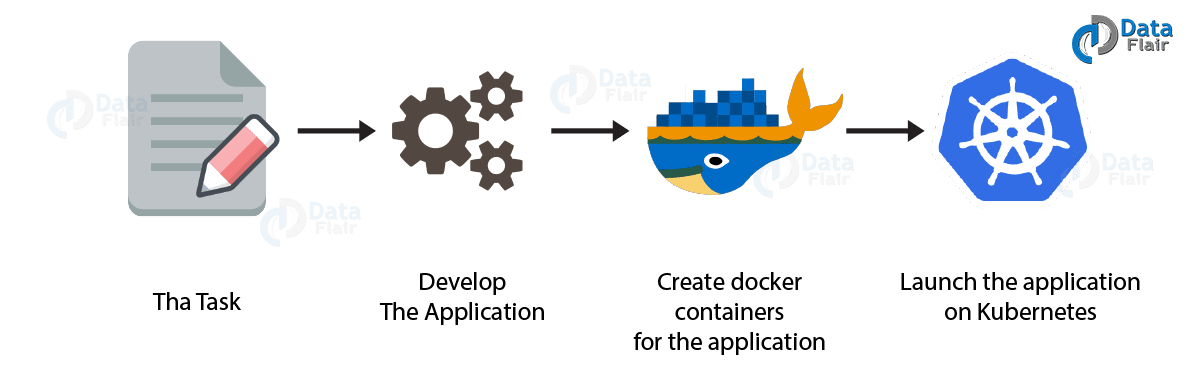
Hence, I can say, using technologies such as containers makes the architecture extremely flexible as well as more portable. Moreover, by using it our DevOps process will get advantage of increased efficiencies in continuous deployment.
The fastest growth in investment in emerging Big Data technologies is in banking healthcare, insurance, securities and investment and telecommunication sectors. Three of these industries lies in the financial sector. And irrespective of sector, Big Data is doing wonders for businesses to improve operational efficiency, and the ability to make informed decisions on the basis of very latest up-to-the-moment information.
Train yourself, your employees for Big Data, Hadoop and emerging Big Data technologies and see the transformation in yourself, your career and your business.


























