





In the era of Data Science where knowledge of programming languages like Python and R is essential to implement the fundamental algorithms and techniques related to Machine learning and Data analytics. Every beginner in this field, especially those from Non-Technical background first tend to learn about the basics of these programming languages then try to implement algorithms related to ML.
Well to make a smooth transition into Data Science, WEKA is such a user-friendly tool where you can start experimenting with a variety of ML algorithms and analytical techniques without having any prior knowledge of programming language.
Waikato Environment for Knowledge Analysis (WEKA) developed at the University of Waikato, New Zealand is free Open source software that provides tools for data processing, implementation of several machine learning algorithms along with visualisation tools so that we can develop machine learning techniques and apply them to real-world data problems.
Stages in WEKA
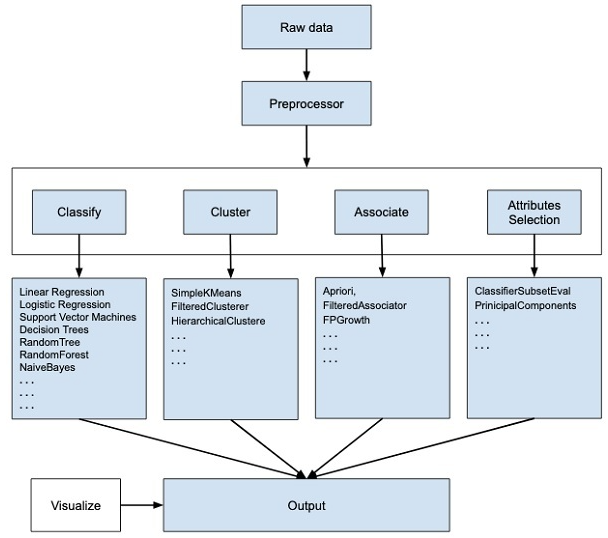
There are many stages associated with WEKA starting from importing the data to applying various techniques. First, after loading the from the field this data may contain several null values and irrelevant fields we can use data preprocessing tools to clean the data.
Next, depending on the type of ML model that you are trying to develop we would select one of the options such as Classify, Association, and Cluster. There is one more known as Attribute selection which allows automatic selection of features to create a reduced dataset.
Now under each of the above categories, WEKA provides several lists of Popular algorithms from which we can choose anyone and setting up parameters we can run on our dataset. After running your desired algorithm WEKA gives results in statistical parameters and also it provides a visualisation tool to inspect our data.
The various algorithms can be applied to the same dataset and we can compare the result of different algorithms and can select the best one which satisfies our needs.
The above stages can be summarized by using the below chart;
To install WEKA on your machine, you need to download windows supported executable fie from WEKA website and it is available for all operating systems. After installing the WEKA you will come with the below interface;

As you can see in the top menu bar there are 4 options Namely Program, Visualization, Tools and Help. Under Program, there are basic settings related to LogWindow, memory usage, and other Miscellaneous settings.
There are two useful options – visualization and tools. Under Visualization, we can visualize our dataset directly with a scatter plot. Similarly, there are various visualizations like plotting ROC, Tree visualizer, Graph Visualizer, and Boundary visualizer. You can explore each one by importing your dataset. Under Tools, there are options like Package Manager, Arff viewer, SQL viewer and Bayes Net editor.
Now as you can see WEKA offers 5 applications. Each one has a different role. Let’s see them one by one;
Explorer
Under explorer basically, we can perform all the activities related to ML and data preprocessing steps. There are all the parameters which we have in the above chart. Here under explorer WEKA prefers arff data type stands for Attribute-Relation File Format it is an extension of CSV file.

The above picture shows the format of the arff file. Here the directive starts with the symbol @ and its preceding with the name for e.g @relation tells the name of the dataset. The directive @attributes gives information about each feature present in data. Under preprocess you can load the following types of files;

After loading it, you can apply various filters to it such as converting nominal values to binary. Based on type data, the filter gets activated. After preprocessing you can apply various techniques to your dataset
Experimenter
A powerful feature of WEKA, unlike explorer i.e for preprocessing the data and applying different algorithms, here the experimenter is for designing and running your own experiments. The results produced by the experimenter are so good that you can use it for publication also.
The experimenter enables us to set up large scale experiments. We can start those experiments, leave them while it is running and we can analyse its performance statistics when it has finished. Under this, we can automate the whole experimental procedure and also it allows the user to distribute learning through many machines using Java RMI.
Here is the interface of the experimenter;

Knowledge Flow
The knowledge Flow presents a data flow, users can select weka components from the toolbar, place them on a canvas and connect them together in order to form a knowledge flow for processing and analysing the data. At present all of WEKA’s classifiers and filters are available at the knowledge flow so you can experiment with it. It is as simple as creating a sketch.

From the tools present on the left side we can prepare a proffer flow chart of our experiment.
Workbench and Simple CLI
The WEKA workbench is an environment that combines all of the GUI interfaces into a single interface. It is more useful when you wish to use more interfaces given by WEKA. If you wish to use Explorer and experimenter at a time you can use them under the workbench.
If you still insist on using codes the WEKA also provides a facility for it. Under simple CLI (Command-line interface) all the above functions can be implemented using WEKA commands. This is very powerful because you can write the shell scripts to use the full API from command lines with parameters that allow us to build models.
The interface of the workbench looks as below;

The interface of CLI;

Conclusion:
From this article, we have seen a simple and easy GUI (Graphical User Interface) based way of learning and experimenting with various tools and techniques related to Machine Learning and Analytics. Beginners can directly start with Explorer, Experimenter, Workbench. Once you master these tools then you can use CLI which is even more interactive.

























