





The overall amount of data is booming like never before that in an unstructured manner. By the end of this decade, it is estimated that we will be having nearly 100’s of zettabytes data and roughly 80% of it unstructured. Unstructured data is nothing but images, audio, text, videos, and so on, and those can not be utilised directly for model building. Nowadays, industries are making an effort to leverage this unstructured data as it can contain a vast amount of information. A huge amount of information available on the internet and taking the right steps on data can result in potential business benefits. By putting the right method to implementation can bring useful insight.
Web scraping, surveys, questionnaires, focus groups, etc., are some of the widely used mechanisms for gathering insightful data. However, web scraping is considered the most reliable and efficient data collection method out of all these methods. Web scraping, also termed as web data extraction, is an automatic method for scraping large data from websites. It processes the HTML of a web page to extract data for manipulation, such as collecting textual data and storing it into some data frames or in a database.
Following are the common use case where web scraping is used;
- Gathering real estate listing
- Website change detection
- Tracking online presence
- Data integration
- Research
- Review scraping from shopping sites
- Weather monitoring
- Data mining
- Scraping data from email
- .. and many more
To proceed with web scraping, we will proceed with a tool called selenium. It is a powerful web browser automation tool that can simulate operations that we humans like to do over the web. It extends its support to various browsers like Chrome, Internet Explorer, Safari, Edge, Firefox. To scrape data from these browsers, selenium provides a module called WebDriver, which is useful to perform various tasks like automated testing, getting cookies, getting screenshots, and many more. Some common use cases of selenium for web scraping are submitting forms, automated login, adding and deleting data, and handling alert prompt. For more details on selenium, you can follow this official documentation.
Static and Dynamic web scraping using selenium:
There is a difference between static web pages and dynamic web pages. In static pages, the content remains the same until someone changes them manually.
On the other hand, content in dynamic web pages can differ from different visitors; for example, contain can be changed according to the user profile. This increases its time complexity as dynamic web pages can render at the client-side, unlike static pages at the server-side.
The static web page content is downloaded locally, and the relevant script is used to gather data. In contrast, dynamic web page content is generated uniquely for every request after the initial load request.
To scrap the data from the web page, selenium provides some standard locators which help to locate the content from the page under test; locators are nothing but keywords associated with HTML pages.

In this article, I’m going to simulate this automated behaviour; firstly, we scrap the data from Naukri.com and make the pandas Dataframe out of it; secondly, we will scrap the user comments from multiple pages Sephora.com using dynamic tagging.
Code implementation:
Install & Import all dependencies:
! pip install webdriver_manager
! pip install seleniumWeb driver manager is used to install drives required for browsers.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import pandas as pd
Initialize Chrome:
Create a variable called driver, which holds an instance for Google Chrome, and further, we will be using the drive variably to initialize commands; driver.maximum window opens chrome on full screen.
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.maximize_window()
The above commands open the window like this;
Open the desired web page:
Next, we will open Naukri.com, which shows a queried result. I have searched for Data Scientist Jobs available over the portal; we scrap the two elements from the page, namely Job tile and Company who provides.
driver.get('https://www.naukri.com/data-scientist-jobs?k=data%20scientist')
Scraping the data:
After opening the web page, you need to inspect the web page by clicking the right button on your mouse; inspection helps you to find Xpath associated with each data available over the page. Inspection is nothing but the HTML view of the page.
The below image shows how to trace the Xpath;
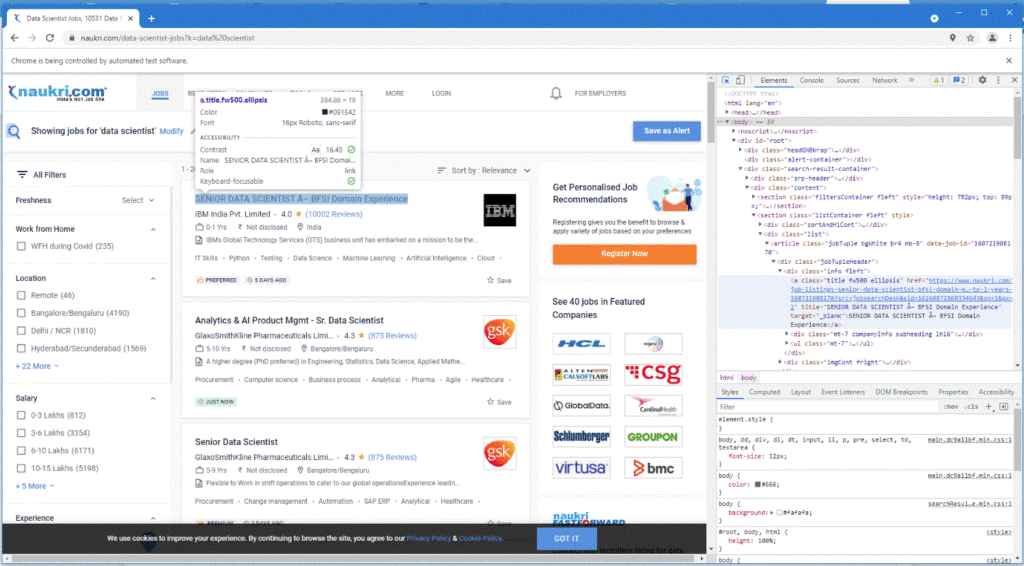
The highlighted element in the inspection console is HTML code for the Job Title; using that, we can create our desired Xpath. X path can be obtained directly by right-clicking to the code, under copy; you can copy it as Xpath, which looks like below;
//*[@id="root"]/div[3]/div[2]/section[2]/div[2]/article[1]/div[1]/div[1]/a
After observing each Job title, you notice that the class name associated with it is the same, so you will scrap the title using the class name as below,
job_title = driver.find_elements_by_xpath('//a[@class="title fw500 ellipsis"]')
So now all the Job names are stored in job_title, so we need to extract that web element using the .text method for each title as below;
title = []
for i in range(len(job_title)):
title.append(job_title[i].text)
titleThe title list shows as below;

The same approach can be applied for our second observation, i.e. company that is offering the job.
Let’s do this all together, an automated script that gives you a Data frame containing the job title and company name available on a particular page.
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.maximize_window()
driver.get('https://www.naukri.com/data-scientist-jobs?k=data%20scientist')
jobs = driver.find_elements_by_xpath('//a[@class="title fw500 ellipsis"]')
company = driver.find_elements_by_xpath('//a[@class="subTitle ellipsis fleft"]')
title = []
for i in range(len(jobs)):
title.append(jobs[i].text)
data = pd.DataFrame(title)
company_ = []
for i in range(len(company)):
company_.append(company[i].text)
data['company'] = company_
data.to_csv('Job List.csv',index=False)
data
driver.close()
Gather data from Multiple pages:
This section will see how to get data from multiple pages; for that, we will visit product sephora.com; from that page, we will take user comments and user names from a few pages.
Firstly we define an empty list for those two variables in which comments and user id will be appended; driver initializing process and scrapping process is the same as previous but change is navigation between pages.
To navigate between pages, we will take xpath from the negation bar of that page; by using that xpath we can navigate between pages.
user = []
commnent = []
#initialize the driver
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.maximize_window()
# open the product page
url='https://www.sephora.com/product/fresh-rose-hyaluronic-acid-deep-hydration-moisturizer-P471237?icid2=new%20arrivals:p471237:product'
driver.get(url)
After scrolling through the page will look like below;

To scrap the data, use inspection console to get xpath shown as below image;

# scrape the data from page
comments = driver.find_elements_by_xpath('//div[@class="css-1x44x6f eanm77i0"]')
user_id = driver.find_elements_by_xpath('//strong[@data-at="nickname"]')
# append the data to list
for i in range(len(user_id)):
user.append(user_id[i].text)
for i in range(len(comments)):
commnent.append(comments[i].text) After appending the data, you can navigate the next page and append data again; the xpath for navigation can be obtained by inspecting page numbers.
# navigate between pages
driver.find_element_by_xpath('//*[@id="ratings-reviews-container"]/div[2]/ul/li[3]/button').click()
data = pd.DataFrame(user)
data['commnents'] = commnent
data.to_csv('Sentiment.csv',index=False)
driver.close()After adding the desired amount of data, we can create a data frame out of it before and the CSV file.
Conclusion:
We have how to scrape data from the web pages; you can use different locators provided by selenium to scrape the data. Scraping from multiple pages will take a bit of time, but it will result as expected. Thus, you can carry out multiple data analysis techniques to derive useful insights and make predictive models out of them.
Reference:
Related Posts


































