





Hugging Face has unveiled a new series of compact language models called SmolLM, available in three sizes: 130M, 350M, and 1.7B parameters. These models are optimised for use on local devices such as laptops and phones, eliminating the need for cloud-based resources and significantly reducing energy consumption.
The SmoLLM models are fully open, with datasets, training code, and models available to the public. They have been trained on FineWeb-Edu and Cosmopedia v2, which will also be released alongside the models. Cosmopedia v2, comprising 28 billion tokens, is the largest synthetic dataset for pre-training, optimized with high-quality prompts across diverse topics.
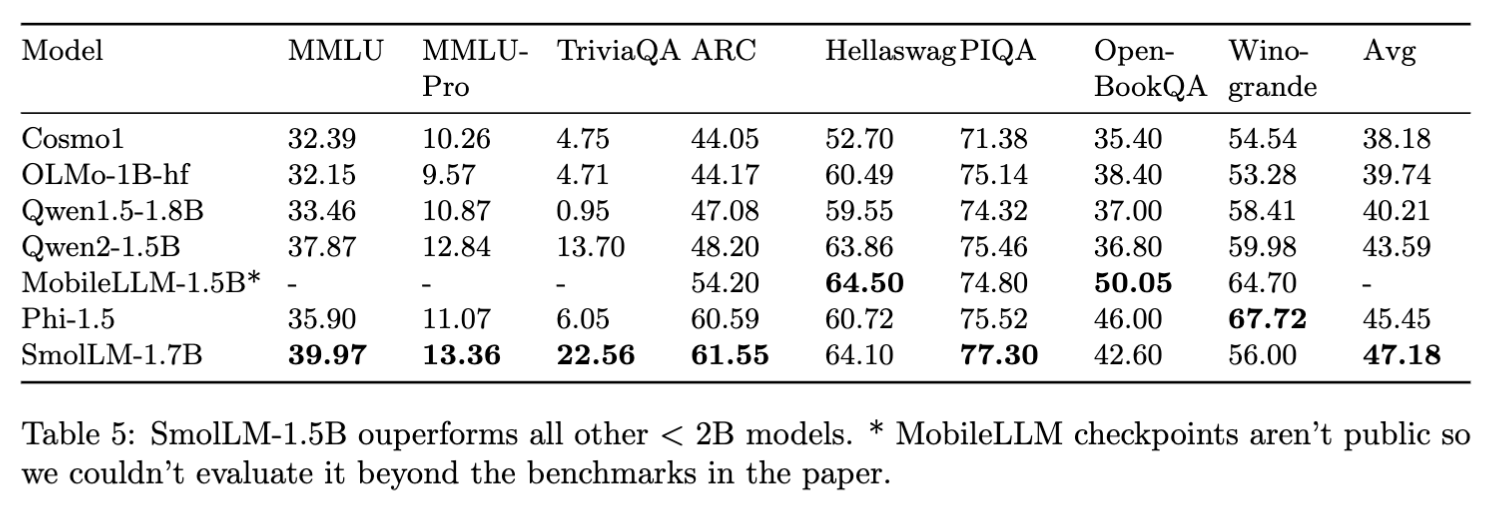
Performance evaluations indicate that SmoLLM models outperform existing models in their respective size categories. The SmoLLM-135M model surpasses the MobileLM-125M model, despite being trained on fewer tokens. Similarly, the SmoLLM-350M and SmoLLM-1.7B models exceed the performance of models like Qwen2-500M, Phi 1.5, and MobileLM-1.5B, with fewer parameters and less training data.
The models are built on the Cosmo-Corpus training corpus, which includes Cosmopedia v2, Python-Edu, and FineWeb-Edu. Cosmopedia v2 is an enhanced version of the original dataset, focusing on effective generation styles. Python-Edu contributes educational samples, while FineWeb-Edu offers deduplicated web samples.
This release highlights the growing interest in small language models capable of local operation, offering advantages in data privacy and cost reduction. Hugging Face’s transparency in documenting data curation and training processes sets it apart from other models like Microsoft’s Phi series and Alibaba’s Qwen2.
The company recently announced its profitability with a team of 220 members while maintaining a largely “free (like model hosting) and open-source for the community!”
Hugging Face recently also unveiled a new open large language model (LLM) leaderboard, with Alibaba’s Qwen-72B model securing the top spot. The leaderboard ranks open-source LLMs based on extensive evaluations, including the MMLU-pro benchmark, which tests models on high school and college-level problems.

























